
第115回 ワークショップ
企業の税制適応行動と戦略策定・政策立案
-税務行動研究のEBPMを通じた社会実装に向けて-
講演
1.Theoretical analysis of non-deductible expenses :
Implications for the design of compensation contracts
村上 裕太郎氏(慶應義塾大学大学院経営管理研究科 教授)
2.課税優遇措置の適用が顕在税および伏在税負担に与える影響
安間 陽加(神戸大学大学院経営学研究科 准教授)
3.探索的財務ビッグデータ解析と再現可能研究
地道 正行氏(関西学院大学商学部 教授)
パネルディスカッション
<パネリスト> 村上 裕太郎氏、安間 陽加、地道 正行氏
<モデレータ> 鈴木 一水(神戸大学大学院経営学研究科 教授)
講演1 Theoretical analysis of non-deductible expenses :Implications for the design of compensation contracts

村上 裕太郎氏
(慶応義塾大学大学院経営管理研究科 教授)
損金不算入費用に関して
慶應義塾大学の村上と申します。本日は貴重な報告の機会をいただき、ありがとうございます。EBPM(Evidence-based Policy Making:証拠に基づく政策立案)を考える際に、なぜ主体の行動原理を考える研究が必要かということに関しては、パネルディスカッションで話します。細かなモデルの話よりは、結果、何が言えるのかと、どういう実証に資するモデルの研究なのかを中心にお伝えできればと考えております。
まず、税金の分野にあまりなじみのない方は、損金不算入の規定をご存知ないかもしれません。損金不算入は、税法上、費用がすべて損金に入るというわけではなく、全部または一部を損金に入れない、つまり、会計上は費用として認めるが、税法上は費用として認めない規定があります。これは、グローバルにどの国でも定められている制度ですが、この分野の研究は、ほとんどなされていないことがわかりました。そこで、本研究は、税務上、事業活動に関連する費用の損金算入を制限する税制が、経営者の努力水準や報酬契約を含む企業行動にどのような影響を与えるかを分析します。また、政府が損金不算入割合を柔軟に動かせるケースも分析します。ちなみにこの研究は、早稲田大学の若林利明先生との共同研究がベースになっています。
北米でよく研究されている損金不算入のテーマとして、ミリオンダラー・タックス・キャップというものがあります。これは、役員報酬の固定給部分に100万ドルの損金算入上限を設けているというものです。現在のレートで換算すると、日本円で1億5千万円超の固定役員報酬に対しては、損金に入れませんという規定がありました。以前は固定給が損金不算入で、業績連動給に関しては上限がない制度でしたが、2017年の税制改革によって業績連動給も損金不算入の対象となりました。それに関するモデルおよび実証の研究もいくつかあるという程度で、それ以外の損金不算入規定に関する研究はほとんどなされていません。損金不算入は、企業にとって非常に重要な話であるにもかかわらず研究がなされていないので、研究すれば企業に対する貢献が大きいのではないかとわれわれは考えました。
例えば、IRS(Internal Revenue Service:アメリカ合衆国内国歳入庁)の条文に、損金算入できる経費の要件として、「ordinary and necessary」と記載されています。「ordinary expense」とは、業界で常識的に認められている費用、「necessary expense」とは、ビジネスをするにあたって役に立つ(売上の貢献に結びつく)費用のことを意味します。
損金算入が制限されている費用のなかで代表的なものとして、接待交際費(Meals&Entertainment expenses)があります。それ以外にも、寄附金や事業と関連性のない教育費、ロビー活動費、罰金、政治献金などが損金不算入費用に該当します。
このような費用は、一般的には売上との関連性が低い「冗費」といわれる無駄な経費として見なされることがあります。損金として認めなければ企業は支出を抑制するので、企業にとって望ましい、というようなことが一般的にはいわれています。しかし、いくつかの実証研究を見ると、損金不算入費用が必ずしも冗費性をもつとは限らないことがわかります。例えば、グローバルに損金不算入になっている慈善寄附が品質のシグナルとして機能したり、あるいはロビー活動費も一部損金不算入になっていますが、ロビー活動していると不正が摘発される可能性が低いとか、中国企業のデータ実証で、ネットワーキング費用(交際費で測定)がR&D(Research and Development:研究開発)費と比べても生産性が低くないという研究もあります。したがって、このような冗費といわれる費用であっても、会社によって、あるいは業界によっては、売上に貢献している重要な費用という可能性があると思います。
交際費などには、もう1つ重要な性質があるとわれわれは考えています。売上との関連性だけで損金不算入の規定を設けているのであれば、研究開発費なども、売上との関連性が相当低いかもしれません。しかし、研究開発費はもちろん全額損金に算入されます。交際費は売上との関連性の他に重要な側面として、productive consumption(生産的消費)という性質があります。つまり、交際費を使うこと自体が経費を使う人のベネフィットになっているということです。例えば、接待交際であれば食事に行き、自分もおいしいものが食べられるとか、スポーツ観戦に得意先を接待すれば自分もスポーツの試合を観戦できるわけです。そのように自らも効用を受けるということも交際費などの費用の特徴であると考えて、それもモデル化をしています。この研究はフリンジ・ベネフィット(企業が役員や従業員に対して給与以外に提供する経済的利益)の研究とも関わってきます。
損金不算入制度を考慮したモラルハザードモデル
本研究では、モラルハザードのモデルを用いて損金不算入制度が報酬契約や最終的には企業価値にどのような影響を与えているのかを分析した研究になります。モデルの設定を見ながら説明を加えていきます。
もう1つわれわれのモデルの大きな特徴として、政府側の行動を考えていることがあります。会計学の研究に関していうと、政府の目的関数を考える研究はほとんどありません。しかしながら、ここ10年くらいにわたり、会計学でも社会厚生を考慮する研究が増えてきました。つまり、政府はどういう理屈でこの損金不算入割合を決めているのかという行動原理を内生化して、モデルの中で解いていきます。それを解くとどういうことが明らかになるかというと、例えば、生産性や税率などさまざまな環境変数がありますが、その環境によって損金不算入を強めたり弱めたりといった話ができます。世界的に見ると、損金不算入規定は似たような制度や異なる制度がありますが、なぜ国によって制度が異なるのか、あるいは、時系列で見たときに、損金不算入は強まっている、弱まっているなど、その理由の一部を説明できる可能性があります。かつて日本では中小企業に交際費の損金不算入規定の上限がありませんでしたが、800万円の上限ができました。大企業では交際費はすべて損金不算入になっていたのが、今は飲食費の50%といった形で一部損金算入が認められるなど変化しています。そのような変化の説明もできるのではないか、ということです。
具体的な理論モデルの説明に移ります。通常のプリンシパル-エージェントのモラルハザードといわれるモデルの設定を紹介します(図1)。株主(Principal)が経営者(Agent)に対して報酬契約を提示します。株主としては頑張って働いてもらうために報酬を出す。特に注目してもらいたいのが、追加的に努力したときの増加分β、いわゆるインセンティブ率です。インセンティブ率にかかっているのがνで、これはパフォーマンス・メジャー(業績評価指標)です。利益だと考えてください。経営者が努力して稼ぎ出した利益(ν)に対して、インセンティブ率βがかかって固定給(α)と足されて報酬(w)が決まるという報酬契約を株主が提示します。このインセンティブ率のβは、株主が自らの目的関数を最大にするように決定します。なぜ経営者に頑張ってもらいたいかというと、経営者を努力させることによって、利益(ν)、つまり株主の期待効用が上がるからです。
 報酬を引く前の利益をまず考えてください。eが努力水準です。経営者が努力して頑張ると生産性のパラメータ(a)がかかり、制御不能な確率的なショック攪乱項(ε)の影響を受けて、利益(ν)が生まれます。したがって、株主としては経営者が頑張るようにβを高めたいと考えています。株主の目的関数である期待効用は、νから経営者に支払う報酬を引いて、課税額を引くという構造になっています。もっともシンプルなモラルハザードモデルでは、税のことを考えていないので、税の支払いは無視されています。われわれのモデルは、課税額を加えていますが、法人税自体が通常の税前所得にそのままかかるという構造ではありません。課税所得(z)は別に定められていますが、税引前利益に損金不算入部分があるので、損金不算入部分を足し戻す必要があります。ここで重要なポイントの1つが、δを損金不算入の割合と定義していることです。
報酬を引く前の利益をまず考えてください。eが努力水準です。経営者が努力して頑張ると生産性のパラメータ(a)がかかり、制御不能な確率的なショック攪乱項(ε)の影響を受けて、利益(ν)が生まれます。したがって、株主としては経営者が頑張るようにβを高めたいと考えています。株主の目的関数である期待効用は、νから経営者に支払う報酬を引いて、課税額を引くという構造になっています。もっともシンプルなモラルハザードモデルでは、税のことを考えていないので、税の支払いは無視されています。われわれのモデルは、課税額を加えていますが、法人税自体が通常の税前所得にそのままかかるという構造ではありません。課税所得(z)は別に定められていますが、税引前利益に損金不算入部分があるので、損金不算入部分を足し戻す必要があります。ここで重要なポイントの1つが、δを損金不算入の割合と定義していることです。
次に、経営者の行動原理について説明します。経営者の効用は、報酬から働くことによる努力コスト(心理的なコスト)が引かれるかたちで定義されます。通常はこのコストを引いて効用関数になっていますが、交際費などの生産的消費という性質を加えるために、努力水準にγという消費財的性質の度合いをかけたものを足しています。これは何かというと、経営者は報酬以外にも接待交際活動から直接、便益を得られる部分があるということを意味します。ですから、重要なポイントとしては、先ほどのインセンティブ率を決めるところで、株主が決めるインセンティブ率(β)に基づいて経営者は努力水準を決めますが、努力水準を決めるときには、経営者はγの影響を受けます。したがって、このγが大きければより努力をしようということになるわけです。一方、株主から見ると、頑張ってくれるのはいいけれど、この活動を頑張りすぎると、損金不算入になる割合が増えてしまうので、そこをどうやってコントロールするかが重要になってきます。
次に、損金不算入割合(δ)を内生化しているモデルを説明します(図2)。行動原理を考える際、政府の目的関数が重要になりますが、このモデルにおいて政府は自らの税収を最大にするようにδを決める構造になっています。

モデルから得られた結果
では、比較静学の結果をお伝えします(図3)。比較静学は、実証仮説のもとになるモデルの性質だと考えていただければと思います。ある変数が動いたときに、注目したい変数がどのように動くのかということを表したものです。まず、図3の上の赤枠にRigid(exogenous)と書いてありますが、これはδが外生変数であるケースに対応します。政府がδを動かさないので、損金不算入の割合は外生変数です。一方、下の赤枠は政府がδを動かす場合で、この場合はδ自体が内生変数になります。損金不算入割合δが内生のモデルでは、どのパラメータ(外生変数)が上がるとδが上がったり下がったりするか、つまり、損金不算入割合が高まったり低まったりするか、ということがわかります。

図3上部の赤枠は、政府の行動原理を考えていない場合のモデルです。tは法人税率です。税率が上がると、株主が経営者にインセンティブをかけることによる企業価値上昇が小さくなるので、インセンティブ率を下げます。そのため経営者は努力しなくなる。EUpは企業価値だと思っていただくと、企業価値自体にもマイナスの影響を与えます。ミクロ経済学の基本モデルでは、法人税は企業行動にニュートラルな税といわれています。つまり、税引前利益を最大化する行動も、税引後利益を最大化する行動も行動原理は変わらない。法人税は「ν-w」に「1-t」をかけるだけなので、「ν-w」を最大化するということに関して、税がかかっても、かからなくても、企業の行動原理は変わらないということになります。このことは先行研究ですでにいわれていることです。しかし、損金不算入の規定があると、法人税率が企業行動に影響を与えて、結果的に経営者の努力にマイナスの影響を与えます。損金不算入割合(δ)は、基本的に法人税率と同じ役割を果たすため、損金不算入の割合が増えると、株主はインセンティブ率(β)を下げ、経営者の努力水準(e)が低くなる結果、企業価値(EUp)が減ることがわかります。
もう1つ見たい変数がγです。γはフリンジ・ベネフィット(企業が従業員に対して給与以外に支払う手当や報酬)の程度にあたります。γに関しては、2つの解釈があると思っています。1つの解釈は、経営者が損金不算入となる活動(接待交際活動など)からどれくらい便益を感じるかという「経営者の特性」を表したものです。もう1つは、どのような損金不算入費用に該当するかという費用のカテゴリーです。例えば、慈善寄附は個人のベネフィットにあまり貢献しない(γが小さい)。一方、交際費や教育費は個人のベネフィットに大きく影響する(γが大きい)かもしれません。直観的には、γが上昇することにより、株主はインセンティブを課さなくても経営者が努力してくれるので、企業としては望ましい結果をもたらします。これはモラルハザードのモデルの常識的なメカニズムですが、経営者はリスク回避的なので、株主がインセンティブを強めると変動給の度合いが高まるため、経営者はそれを嫌います。そのリスクを補填するために固定給を払わなければいけないのですが、株主としてはできれば経営者に金銭的インセンティブをかけなくても頑張ってもらいたい。それがγのおかげでできるわけです。例えば、経営者が会食が好きだということで頑張ってくれると、βを節約できる(報酬を抑える)ことになるので企業にとっては良い。この結果は、いくつかの先行研究で示されています。γだけではなくて、企業に対する帰属意識などのさまざまな要因でインセンティブ率をセーブしながら経営者を働かせることができると、企業にとっては望ましいことが知られています。
次に、損金不算入の割合(δ)を内生化した場合、どのようなパラメータが損金不算入の割合に影響を与えるか、ということをお話しします。まず、法人税率が高くなると損金不算入割合を低めます。今、グローバルでは法人税率は下がる傾向にありますが、税率が下がっている中では、逆に損金不算入割合を上げる傾向があるということが、モデルから明らかになりました。次に、生産性(a)が高くなるということは、売上高あるいは利益と交際費支出との関連性が高まるということを意味します。そういうときには、損金不算入の割合を引き下げていくのが直観的だと思います。われわれの結果でも生産性上昇とともに損金不算入割合を引き下げていくという結果が得られる一方、プラスになるケース、つまり生産性の上昇とともに損金不算入割合を高めるというケースも出てきます。それはどういうケースかというと、例えば、γに依存します。γとは、その行為からどれだけベネフィットを受けるかです。ベネフィットを受ける度合いが高いときには、経営者はその交際活動自体からも効用を得るため、インセンティブをかけなくても接待活動をします。このときに生産性が高くなると、自分の努力がよりパフォーマンスメジャーである利益に跳ね返ってくるので、より頑張る。しかもγも強いとなると、さらに頑張る。このような条件下で政府が損金不算入割合を引き下げてしまうと、経営者のさらなる過大な接待活動を誘発してしまうことになります。したがって、政府としては損金不算入割合を引き上げて交際活動を抑制させたほうが税収を取ることができるのです。
次に、γとδの比較静学について説明します。γが上がると、政府は損金不算入割合を上昇させます。先述したように、γが高いとき株主はインセンティブ率βを引き下げます。γが高いとき、より経営者は交際活動からベネフィットを受けるということなので、インセンティブをかけなくても経営者は働いてくれるからです。このときに政府が損金不算入割合を引き下げると、経営者は過大な交際活動を行なって課税ベースであるzが減少してしまうため、政府にとっては税収が減ってしまいます。このときには、政府は損金不算入割合を引き上げることでより大きな税収を得ることができるのです。
損金不算入割合が内生的な場合と外生的な場合で、企業価値に関する比較静学が異なることは面白いと思っています。δが外生のときは、税率が上がるとインセンティブ率にも企業価値にもマイナスに影響しましたが、δが内生のときには、損金不算入割合を政府がコントロールすることで、企業に良い影響を与える可能性があります。これは、先述したように法人税率が高まると政府は損金不算入割合を下げることに起因しています。後で紹介しますが、δを柔軟に変更可能かどうかは、国ごとの政策変更コストの大きさに起因していると考えられます。このモデルからの比較静学の結果は、損金不算入割合が内生か外生かで結果が異なることを示唆しているため、実証研究を行なう際は、政策変更コストの異なる国ごとに影響が異なる可能性を示しています。
実証研究へのインプリケーション
では、モデルから得られた結果がどのように実証研究に資するか考えていきましょう。特に大事なポイントとして、γは損金不算入となる費用のカテゴリーと解釈できます。つまり、接待交際活動などはγが高くなりますし、慈善寄附などは相対的にγが低くなると考えられます。近年、実効税率調整表のデータを使った研究が海外で増えてきていて、今は大規模データをプログラミングによって自動取得しているようです。先行研究は「Valuation allowance」といわれる評価性引当額に注目した研究が主ですが、実効税率調整表には興味深い情報が載っています。
損金不算入割合(δ)や損金不算入費用の中でベネフィットを受けられそうな費用の割合(γ)は、どのようにデータとして取得することができるでしょうか。図4 は、トッパン・フォームズの例ですが、交際費の損金不算入額(永久差異)の影響で実効税率と法定税率の違いにどのような影響を与えているのかがわかります。次に図5のKDDIの例では、交際費に限らず損金不算入費用が実効税率を3%弱押し上げています。


例えば、δは図5の「税務上損金不算入の費用」から推測することができます。難しいのはγですが、企業によっては損金不算入費用を交際費・慈善寄附などの費目別に分けている場合もあり、その場合は一定の仮定のもとγを推測できるかもしれません。
海外の開示情報も見てみましょう。ここでは、Red RobinというハンバーガーチェーンのMeals&Entertainmentを例に挙げ、交際費が実効税率にどれぐらい影響を与えているかを見ることができます(図6)。

損金不算入費用全般については、半導体関連のASM Internationalの開示例を紹介します(図7)。図7の赤枠で囲ったように、「Non-deductible expenses」という形で開示されています。以上より、実効税率調整表の開示情報を使うと、損金不算入費用の割合(モデルのδに該当)の数字を捉えることができる可能性があります。

比較静学の結果が政策変更の柔軟性(損金不算入割合が内生か外生か)によって変化するため、政策変更が柔軟か否かを考慮したクロスカントリーの研究が重要になると述べました。では、政策変更が柔軟かどうかをどのように定量化したらよいでしょうか。1つは政治経済学の分野において、政策変更の柔軟性を定量化している研究があります。Henisz (2000)[2]は政党の強さや二大政党制かどうかといった要素を考慮しながら、政策変更はどれぐらい起こりやすいかを定量化しています。ただし、Henisz (2000)の指標が税制変更の柔軟性に適用できる保証はありません。では、税制を変更しやすい、しづらいということについては、Atwood et al. (2010)[3]の研究が参考になります。彼らのBook-Tax Conformity(BTC:会計利益と課税所得の一致)に関するクロスカントリー研究では、課税所得と会計利益がどれぐらい近いか国ごとに計測し、税引前利益と法人税費用の関係を国ごと、年ごとに推計してBTCを計測しています。例えば、税引前利益と法人税の関係は、税制の変更がなければそれほど変化しないので、パラメータを年度で比較していくと、変化しやすい国なのか、しづらい国なのか、ある程度わかるのではないかと思います。
研究内容と成果のまとめ
本研究の内容および成果をまとめます。交際費をはじめとする損金不算入の規定が、経営者や株主にどのような影響を与えるのか分析することが本研究の目的でした。経営者報酬に影響を与える業績指標は税前利益であるため、経営者自身の行動に直接税関連の変数(法人税率および損金不算入割合)が影響を与えることはありません。しかし、株主は企業としての税負担が増えないように経営者の報酬(インセンティブ率)をコントロールすることによって企業価値を最大化します。交際活動は、活動自体が経営者に便益を生む生産的消費という性質をもつため、株主は経営者にそれほどインセンティブを強めなくても働いてもらえるメリットはありますが、生産的消費の度合いが強い(経営者が交際活動から感じる便益が大きい)と、過大な接待活動のせいで損金不算入費用が増えるというトレードオフに株主は直面します。
もう1点、政府の行動原理を内生化したことによって、損金不算入割合を動かせる場合と動かせない場合で比較静学の結果が異なることがわかりました。つまり、損金不算入割合を柔軟に動かせる国と動かせない国で実証仮説を変えていかないと、その結果が混在してしまう懸念があります。
さらに損金不算入割合を内生化することによって、なぜある国は損金不算入の割合が高いのか低いのかとか、時間を通じて厳しくしてきたのか、緩くしてきたのかを、部分的に説明できる可能性があります。
講演1の質疑応答
鈴木 単なる理論分析にとどまらず、実証研究への拡張可能性まで説明していただき、ありがとうございました。何かご質問のある方、いらっしゃいますか。
質問者A 私は普段、税周りの業務をしているわけではないので、講演の内容とずれた質問になるかもしれませんが、2つ質問します。
比較静学について、私は初めて聞きました。仮説の表示がプラスとかマイナスになっていますが、これはどうやってつけられているのかというのが1つ目の質問です。
もう1点が、δを損金算入割合として置かれていますが、政策変更が硬直的な場合には努力水準がマイナスとなりますが、そこがよく理解できませんでした。企業としては税制の効果は受けられないけれど、経営者個人としては、何かつながっていくのかもしれない。直接の関係性はないと思ったので、税制で優遇されないからといって、経営者が努力しないということには、必ずしも論理的にはつながらないと思ったのですが、その辺はいかがでしょうか。
村上 まず、プラス・マイナス表示するのは、実証研究でも同じだと思います。いろいろな理論があると思いますが、実証研究の場合は、言葉で理論を導き出して事前の符号予測をします。理論研究の場合は、モデルにもとづいて数学の結果として符号条件を導出します。つまり、外生変数(説明変数)が上昇したときに内生変数(目的変数)が上昇するかどうかを数式から導くことができるということです。理論モデルの重要な前提として、世の中にあるもの(変数)をすべて考えるということではなくて、プラモデル(模型)と一緒で、分析をしたいところの骨組みだけを取り出して分析をするという感じです。いろいろなものを入れてしまうと、いろいろなものが動いてしまうので、そうではなくて、自分たちが見たいところだけを取り出した模型を作って、動かしてみて、これが動くところだけを見ているということです。
2点目ですが、このモデル自体は、おっしゃる通り、損金不算入の割合が増えようと、経営者が努力する、しないと直接の関わりはないのですが、経営者が努力するかどうかは報酬契約に依存しています。株主としては、交際費の水準が高くなると税支払いが増えてしまうため、この報酬契約を通じて経営者の接待交際活動を抑制し(努力水準を下げ)ます。
質問者A ということは、損金不算入割合が高いと、インセンティブ契約の中に取り入れていこうとすると、結果として報酬額が下がって、経営者が努力する割合が下がるのではないか、ということですね。
村上 そうです。δが増えると一般的にはβを下げます。βを下げて、そんなに頑張らないようにさせるということです。頑張らないようにさせないと、損金不算入のところで税額が上がってしまうというメカニズムです。
[1] Murakami, Y., & Wakabayashi, T. (2024). Theoretical analysis of non-deductible expenses: Implications for the design of compensation contracts. Journal of Accounting and Public Policy, 45, 107195.
[2] Henisz, W. J. (2000). The institutional environment for economic growth. Economics & Politics, 12 (1), 1-31.
[3] Atwood, T. J., Drake, M. S., & Myers, L. A. (2010). Book-tax conformity, earnings persistence and the association between earnings and future cash flows. Journal of Accounting and Economics, 50 (1), 111-125.
講演2 課税優遇措置の適用が顕在税および伏在税負担に与える影響

安間 陽加
(神戸大学大学院経営学研究科 准教授)
神戸大学大学院経営学研究科の安間と申します。このような貴重な報告の機会をいただきありがとうございます。私からは伝統的なアーカイバル実証研究(会計データを用いて定量的な分析を行う研究手法)の成果について、「課税優遇措置の適用が顕在税および伏在税負担に与える影響」という報告をします。
最近、賃上げのニュースがよく出てきていると感じられているのではないかと思います。税制面からも企業の賃上げを促進しようという優遇措置がいくつか施行されているという現状です。本研究は、それに着目した研究になりますので、制度の概要を簡単に説明した後に、この税制を利用していると思われる企業の特徴と、企業の総合的な税負担がどう変化したのか、また、税制を利用したと思われる企業に税制がどういった影響を与えたのかという点について報告します。
税務計画の目的と伏在税
タイトルに「顕在税(Explicit taxes)」と「伏在税(Implicit taxes)」という言葉を入れていますが、この言葉を初めて聞かれる方もいらっしゃると思うので、まずはそれについてお話しします。
今回の税務会計分野における理論研究やデータを使った実証研究のベースにある議論として、1990年代にScholesと Wolfsonが提唱した理論的な分析枠組みがあります。この分析枠組みにおいて強調されているのが、有効なタックスプランニングとは何か、という点です。企業の目指すべき合理的なタックスプランニングとしてイメージされるのは、支払税額の最小化だと思いますが、Scholes と Wolfsonは税額を安くするのではなくて、税引後のキャッシュフローを最大化するのが、合理的なタックスプランニングの目的であると強調しています。
この税引後のキャッシュフローを最大化するためには何が必要かということで、4つの包括的な視点が必要であると提唱しています。その4つの視点は、①すべての利害関係者への影響、②すべての税の測定、③すべてのコストの節約、④すべての課税管轄、になります。この4つの視点を考慮して、合理的なタックスプランニングの目的である税引後キャッシュフローの最大化を目指すべきだといわれてます。
この4つの視点に、「すべての税の測定」がありますが、「すべての税」の中には今回のタイトルに挙げている「伏在税」が、含まれています。「すべての税の測定」の視点から見ると、税務計画の際に、税務当局に対して支払われる税金の他に、課税優遇投資の税引前投資収益率の低下という形で間接的に負担される伏在税を考慮しなければ駄目だということです。税務当局に対して支払われる税が「顕在税」で、これは税務署に申告書を提出して国や地方に納付している税金です。企業が負担してる税金は顕在税だけではなく、伏在税も負担しています。そのため、伏在税を考慮しないと、税引後キャッシュフローの最大化を達成できないといった議論が展開されています。
この伏在税について検証した研究は、あまり多くありませんが、最近、日本でも研究は増えていて、いくつかの実証証拠が提示されてきていますが、潤沢に証拠が蓄積されているとは言えないのが現状です。
企業の負担している税金には、先ほど申し上げた通り、顕在税と伏在税の両方があります。顕在税とは、一般的にイメージされる課税当局に対して支払う税金です。伏在税は、課税優遇投資の税引前投資収益率の低下という形で間接的に負担される税であると定義され、課税優遇を受ける投資からの税引前収益率が、課税優遇されない投資からの税引前投資収益率を下回った場合の差として測定されます。同一のキャッシュフローを生み出す資産(投資対象)が2つ存在し、片方は税優遇されて、片方は税優遇されないという状況があったら、一般的に税優遇される方を選ぶと思います。しかし、需要過多となれば市場価格は上がるので、税優遇を選んだ結果、価格が上がって、そこから得られるリターンは減ってしまう。それは、税引前のキャッシュフローを低下させてしまいます。結果的に合理的なタックスプランニングの目的だといわれている、税引後のキャッシュフローの最大化が実現できなくなってしまうという問題が生じます。この伏在税はすごく重要な要素ですが、実証的な検証に取り組むにはさまざまな壁もあり、十分には実現できていないのが現状です。
とはいえ、いくつかの先行研究は存在しています。しかし、海外の先行研究でも「Implicit taxes」というキーワードを挙げている研究は限定的で、数えるぐらいしかありません。最近のトレンドとして、企業レベルの検証が挙げられます。つまり、企業レベルでの税引前投資収益率の変化を検証した先行研究がいくつか出てきています。ただ、それもさほど多くはないというのが現状です。
伏在税は、課税優遇措置が施行されている状況下においては、理論的には存在するといわれています。ただ、それが実際に生じているのかについては、取り組まれていない課題でもあるので、今回、世間で騒がれている賃上税制を1つの外的要因と捉え、伏在税の存在も考慮した研究をしていこうというのが、本研究のモチベーションになります。
所得拡大促進税制の制度概要
賃上げに関しては、最低賃金を1,500円にしようという議論が盛り上がり始めています。2023年末はより議論が盛んでした。これには令和6年度税制改正大綱で、賃上げ税制についてより強力的な制度にしていく、という議論がなされた背景があります(図1)。

賃上げを促進するための課税優遇措置は、2013年に初めて施行されました。2013年に所得拡大促進税制が施行されて以来、現在に至るまで計4回改正が行われています。本当に何が変わったのか疑問もありますが、優遇措置などで時限立法という形をとりながら、それが終わるタイミングで、名前や適用要件を変えながら改正を繰り返しているという状況です。
本研究は、図1の賃上げに関する課税優遇措置の4つのうち、最初に施行された所得拡大促進税制に着目しています。というのは、実証研究における都合でもありますが、日本におけるさまざまな税制、優遇税制は以前から同じような制度が引き続き施行されている状況です。設備とか、研究開発など、何年も前からある制度が非常に多い。そんな中、この所得拡大促進税制は、2013年に初めてできた制度です。制度が初めて施行されたときの影響を見るには、私たち研究者にとっては非常にありがたい状況です。ということもあり、今までなかった制度が導入された際、企業はどのように行動するのかに着眼点を置き、制度を利用したであろう企業の税負担にこの税制がどのような影響を及ぼしたのか、という点について検証を試みました。
そもそも2013年に、なぜこの所得拡大促進税制ができたのか。当時は、リーマン・ショック後で、国民の給与水準はあまり高くありませんでした。給与所得の水準、個人の所得水準を回復させ、景気回復につなげていく政策ができないかということで、創設された制度です。個人の所得水準をどうやって底上げして上昇させるかを考えたときに、一生懸命働いたとしても、賃金はそれほど上がらない。そこで、企業が従業員に対して支払う給与を増額したら、企業の税金を安くするという、企業側に税インセンティブを提供する制度ができました。
この制度は、基準年度と比較して5%以上給与等支給額を増加させた場合に、増加分の10%を企業の税金から引くことができる。つまり、具体的に税額控除という形で税額を減らすことができる制度になっています。この制度を実際に使うためには、図2にある3つの要件を満たす必要があります。一番大きいのが1つ目の「基準年度と比較して5%以上給与等支給額が増加」です。ここに記載のある3つの要件をすべて満たすとこの制度が使えます。

制度施行当初は、給与等支給額が5%以上増加したら、この制度を使えるという制度でしたが、5%の設定が厳しかったのか、施行1年後に、この要件が遡及適用で2%に緩和されました。そして、2%から5%に段階的に戻っていく制度設計に改正されました。
日本では、財務省がこういった優遇措置の効果について、実際の適用件数はこれだけありますとか、これだけの適用総額です、というデータを一覧として出しています。ただ、これは上場・非上場を問わない数字なので、実際に件数だけ出されても、果たしてそれが多いのか少ないのかも、判断が難しいところがあります。この点も、制度設計の事後評価にあたっては問題となってくると感じています。
課税優遇措置に当たる所得拡大促進税制は新しい制度ですが、日本特有の制度なので先行研究が限定的な状況です。そこで、他の課税優遇措置に関する先行研究を参照するため、いくつかの先行研究をピックアップしました。
課税優遇措置に関する研究は、設備投資や研究開発がメインになってきます。というのも設備投資や研究開発を促進する税制は、日本だけではなく諸外国にもあるので、諸外国において、各国の制度の影響を実証的に検証した先行研究がいくつか存在しています。
先行研究では、設備投資や研究開発投資を促進するための優遇措置の施行により、企業が本当に設備を増やしたのか、研究開発に本当に一生懸命取り組んだのか、といったリサーチクエスチョンから検証しているものがほとんどです。また、タイトルにも挙げている伏在税に直接的にフォーカスした検証研究も少ないながらも存在していて、設備投資の税制が施行された間に、優遇対象の価格が変化しているかどうかを検証しているものもあります。多くの研究は、この優遇措置が企業行動にどういう影響を与えたかを分析していて、優遇措置が一定程度、投資促進のための政策効果を持っているという分析結果が提示されています。
本研究の分析においては、限界税率(所得の追加1円に対して増減する税額の現在価値)という概念に着目しています。今回、着目した所得拡大促進税制に関する先行研究をいくつかピックアップしました。これらの多くは、シンクタンクの研究者が「こういうことがありそうだ」と意見しているものですが、アンケート調査を行ったものもあります。例えば、2017年の株式会社パイプドビッツの研究は、アンケートで所得拡大促進税制を利用したと回答した企業のうち、多くの企業が、この優遇措置の利用が賃上げを後押ししたと比較的ポジティブな回答をした、と述べています。
一方、この所得拡大促進税制は給与を増やすので、企業にとっては固定費の圧迫につながる可能性があります。となると、設備投資や研究開発投資のように、一回やって終わりというわけではない。一度ベースアップしたら、それを維持し続けなくてはいけないという難しさもあって、この点に対するネガティブなコメントもいくつかの研究で言及されています。基本給を一度上げてしまうと、引き下げるのが難しく、中長期的な固定費だと捉えると増大していくので、企業の財政状態を圧迫させるのではないかといったネガティブなコメントも出ています。
ネガティブポイントの特徴は、基本給を上げた後に、「今年からは下げます」と簡単には下げられないという点です。基本給の増額は他の投資と比べて支出額に対する重要性が低いのですが、このようなネガティブな特徴を持った投資に対して税の側面から、ベネフィットを与えたときにどうなのか、とても重要な問題になってくると認識してます。
所得拡大促進税制の影響に関する検証
本研究では、こういった制度が初めて施行されたときに、その制度を利用している企業がアウトカムとして税負担の削減にそもそも成功しているのかという点と、その制度を利用している企業が税負担の削減に成功していたとしても、本当にトータルで成功に値するのか、という問題意識から3つの仮説を立てています。1つ目は制度の仕組み上、一般に税負担の高い企業、つまり限界税率が高い企業は、自身の顕在的な税負担を削減する行動をとるといわれている点についてです。この課税優遇措置は、顕在的な納付税額を削減する効果を持っている制度設計になっているので、税負担が高い企業の方がこのような制度を積極的に利用するでしょう。通常の設備投資や研究開発投資といった他の優遇税制においても、限界税率が重要な要因として挙がっていて、税金の高い企業の方が積極的に投資をするといわれています。この所得拡大促進税制についても、限界税率の高い企業の方が所得拡大促進税制をより利用するという仮説を立てています。
次に、課税優遇措置は、顕在的な税負担を減少させる効果を持っています。というのも、課税優遇措置は、特別償却や税額控除という形式を採用しているので、明示的な税負担を減少させる制度設計になっています。この制度を利用することで企業が自身の税負担の削減を成功させているかどうかという顕在的な税負担帰結について、2つ目の仮説で検証したいと考えています。
3つ目が伏在税についてです。課税優遇措置は、企業の顕在的な税負担を減少させる効果を持っていますが、その一方で、税引前投資収益率を減少させる可能性が指摘されています。これが伏在税の存在です。伏在税は理論的に存在するといわれてますが、それが存在すれば、優遇措置を利用している企業は、課税優遇を受ける代わりに、優遇対象の税引前収益率の低下を受け入れていると考えられます。この所得拡大促進税制についても同様のことが想定されるので、所得拡大促進税制を適用する企業は伏在税を負担するという仮説を立てました。優遇対象資産は、給与の増額で一見わかりにくいのですが、人的資本投資と捉えられると考えています。企業が人材投資や人的資本投資することで、それが課税優遇対象資産と捉えられ、結果的に税引前の収益率の低下を招いてしまっているのではないか、という仮説です。
分析モデルは、今回3つ用意しています。1つ目は、限界税率がそもそも企業の優遇税制の利用に影響を与えているのかどうかを検証するためのモデルです。2つ目が、企業の経済的な税負担にこの制度利用がどういう影響を与えるかという点について検証するモデルです。3つ目が、企業の税引前投資収益率にこの制度の利用がどういう影響を与えるかというモデルです。3つ目のモデルですが、1つの投資から得られるリターンを個別に識別するのが難しいため、トレンドに沿って企業レベルでその優遇措置を利用している企業全体の投資収益率、税引前利益が減っているか増えているかどうかを検証したモデルになっています。
通常の税制研究や実証的な研究においては、外部の人間が申告書を見ることができないので、企業がどの制度を使っているかを特定することは基本的にできません。そこが検証における大きな壁になっています。分析者側のありがたみとしては、所得拡大促進税制については3つの要件が明確に決まっているので、公表データから制度を利用しているであろう企業が特定できます。この要件を満たした企業を、課税優遇措置の利用企業であると仮定して分析を行いました。
定義としては、3つの要件を満たしている企業を1とするダミー変数を採用しています。どの年度かということも問題ですが、制度施行後において1回でも1に該当した企業は、利用企業としています。今回、その企業の特定が仮定ではありますが可能になったということで、DID(Difference in Differences:差分の差分法。量的調査に用いられる観測データを利用した因果推論の方法)の手法を使って推定を行っています。つまり、制度施行後において、制度を使っているであろう企業の税負担がどうなのか、税引前投資利益がどうなのかを検証しています。限界税率や税負担については、先行研究などを参考にしています。
分析結果については次の通りです。限界税率が高ければこの制度を利用する、という仮説については、限界税率が高い企業の方が、その制度を利用する選択確率はプラスに影響を与えていることが明らかになりました。
制度施行後の利用企業の税負担は、一部有意ではなかったのですが、基本的には顕在税の負担は減少していると解釈することができると思います。3つ目は、制度を利用する企業の税引前利益が税制施行後において、どういった影響を受けているかということですが、予想通りマイナスの影響が出ています。
以上から、次のことが言えると思います。基本的に限界税率の高い企業は、所得拡大促進税制を利用しており、所得拡大促進税制を利用していると思われる企業の顕在税負担は、制度施行後において減少しています。また、所得拡大促進税制適用企業は、制度施行後において、税引前利益の低下を受け入れています。つまり、伏在税を負担していると解釈できるのではないかということです。
本研究の含意としては、限界税率の高い企業がこの税制を適用しているという傾向が見受けられました。これは他の課税優遇措置でも同様の傾向が見られます。こういった制度が施行されたときは、企業は顕在的な税負担の削減を一種の目的として、課税優遇措置を利用していることが結果として得られると思われます。
また、所得拡大促進税制の適用企業は、優遇措置の利用によって顕在的な税負担を減少させることに成功しています。つまり、課税優遇措置の持っている効果が、企業のアウトカム、顕在税の削減、節税という言葉が適切かどうかわかりませんが、そういったところで成功していることが示唆されます。3つ目として所得拡大促進税制の適用企業の税引前利益は、制度の施行後に減少していることが結果から見えたので、顕在税の負担を軽減させることを成功させている一方で、おそらく、伏在税を一定程度負担しているのではないか、ということが示唆されます。
本研究の貢献点は、2点挙げられます。まずは伏在税の研究が、そもそもとても少ないという現状において、特定の優遇措置の利用によって伏在税が生じている可能性があることを明らかにした点です。また、特定の制度利用が企業の税負担に与える影響の解明は、データ入手の難しさから行われてきていないという現状があります。そのような中で、制度の3つの要件を満たしている企業を分析することで、顕在税と伏在税の両方について明らかにすることに挑戦したという点です。企業がどの制度を使っているか、どういった意思決定をしているかという点について、申告書を直接見ることができないので、判断がつきません。何をしたから税負担が減少しているというデータの入手が難しく、そういった点からも、貢献につながるのではないかと感じています。
この制度の目的は、個人の所得水準を上昇させることが掲げられています。制度を施行したことによって、どの程度、所得水準を上昇させているか、という因果については、本研究においては検討できないという点が課題として挙げられます。
こういったことが明らかになると、資金に余裕のある企業が給与等の増額を実施できているとしたら、リッチな企業とそうではない企業の格差が広がるのではないかという議論にもつながると思いますし、その議論から、個人所得水準の底上げという、この制度の本来の目的を達成できる制度設計になっているのかという議論にも広がるのではないかと考えています。
伏在税の存在の可能性は、今回、一定程度示せたとは思いますが、なぜ伏在税が議論されるのかについては、結局のところ、企業価値を低下させる可能性があり、企業価値の毀損(きそん)につながる可能性があるという点が懸念事項としてあります。それを直接的に検討することは、本研究においてはできていません。
もう1つ、今回は3つの要件を満たしている企業が制度を利用していると仮定していますが、本当にこの制度を利用しているかどうかは正確には把握できないので、注意しなければいけない点だと感じています。つまり、要件を満たしているから自動的にその制度を利用しているとはならず、要件を満たした上でさらに、「私はこの制度を使います」という意思表示をしないと、こういった制度は使えません。意思表示をするかどうかというところまでは、データからは検討できないということで、その解釈については、注意しなければいけないと考えています。
また、税引前投資収益率の測定ですが、今回は企業レベルということで、企業の税引前利益を代理変数として使いました。しかし、企業が適用要件を超えてプラスアルファで払っている給与部分が、本来の伏在税であると定義できるかもしれません。ただ、分析の手法上の問題もあって、そこまでは検討できていないので、この点についても解釈に注意が必要であると、最後に限界点として挙げさせていただきました。
講演2の質疑応答
鈴木 何か質問がございますでしょうか。
質問者B 興味深い研究のお話をありがとうございます。奥が深いと思いながら聞いていました。この所得拡大税制があろうとなかろうと、賃上げをすると税金は減るし、企業のインカムも減るのは変わらないのではないかと思うのですが、齟齬があればご指摘ください。
安間 人件費部分が損金に反映されるから、結局、自動的に減るのではないかということでしょうか。
質問者B そうです。あろうとなかろうと、賃上げすれば、この結果になるのではないかと思いました。
安間 なるほど。今回はDID手法を使って、制度利用しているであろう企業の結果を示しています。人件費部分を損金に算入することができるからプラスアルファの影響がなくても、こういった結果が出るというのは確かに考えられるかもしれません。それが最後に話した限界の部分にもつながっていて、本来なら伏在税の負担をこの要件以上の給与への影響を考慮しなくてはいけないのが、今回はできていないので、その辺りが関係してくると思います。
質問者B なるほど、だから奥が深いなと思いました。ありがとうございます。
鈴木 私も同じ疑問があって、賃上げしたら税引前利益が下がるのは当然だと思います。DIDで分析するなら、例えば、労働生産性とか付加価値に変化がなかったとか、あるいは賃上げしたのに税引後利益率は変化しなかった、ということを証明する方が、伏在税の存在証明になるのではないかと思います。
安間 労働生産性に関しては以前に一度分析しましたが、それはアウトカムとはとらえにくいので、アウトカムへの影響をみてはどうだろうか、というご指摘を受けたことがあります。
鈴木 人件費が上がったにもかかわらず、労働生産性に変化がないということが大事です。賃上げしても、付加価値は変わらないとか、税引後利益は変わらないとか。
村上 税引後の場合、ETR(Effective Tax Rate:実効税率)は下がっても、顕在税と混ざってしまいます。
鈴木 伏在税が存在すると、顕在税と合計で税負担が変わらないのだから、人件費が上がっても、減少した顕在税を足したら、前と一緒でしたという状態で伏在税が存在していることになるのではないでしょうか。
安間 税引後で均衡しているということですか。
鈴木 そうです。
安間 わかりました。貴重なコメント、ありがとうございました。
講演3 探索的財務ビッグデータ解析と再現可能研究

地道 正行氏
(関西学院大学商学部 教授)
関西学院大学の地道です。専門は数理統計学、統計科学、データサイエンスと呼ばれる分野で、その中でも専門領域は回帰分析、特に多重共線性を研究してきました。最近は、弊学の阪智香先生と一緒に、探索的データ解析に基づいて財務ビッグデータを可視化、統計モデリングしています。ソフトウェアは主に「データ解析環境R」を使っています。
本来は、統計科学が私の専門分野ですが、データ解析を行うための環境、例えばコンピュータなどのプラットフォームを考えることにも興味があります。特にデータベースやスーパーコンピュータなどを使用して研究する方法を検討することなどです。
データの前処理・ラングリングと探索的データ解析
探索的にデータを解析することや、それを実現するための工程を概念図として示しています(図1)。与えられたデータをそのままソフトウェアに読み込んで解析できるのであれば、非常にハッピーだと思いますが、それが難しい場合が多くあります。データを読み込む段階まで持っていくのに長時間かかった経験がある方もいらっしゃるのではないかと思います。われわれは、読み込む前の工程を「前処理」(preprocessing)と呼んでいます。また、たとえ読み込めたとしても、さらに変換などのさまざまな処理を追加で行わないと、分析可能なオブジェクト形式にできないことが往々にしてあります。その工程を「データラングリング」(data wrangling)と呼んでいます。われわれが指針としている探索的データ解析というリサーチメソッドは、このようなオブジェクト形式にデータを変換した後に実行します。

「探索的データ解析」(Exploratory Data Analysis: EDA)、「データ解析」(data analysis)、さらに、「解析」(analysis) という言葉を作った人が米国の数学者・統計学者、もっと広い観点では科学者のJ. W. Tukey(John Wilder Tukey)です。彼の提唱した探索的データ解析のオリジナルの考え方に基づいて研究を行おうとするのが、われわれの方針です。最終的には推測した結果や意思決定につなげる論文を書いたり、それを含めて全体を「再現可能性」 (reproducible) をもたせて実行することを意識して、これまで研究を行ってきました。このようなことを試みている理由は、再び得ることができない研究結果は科学的でないと思われるからです。社会科学でもその考え方は重要だと思います。
探索的データ解析を実行するのは、さまざまな解釈があると思いますが、われわれが指針としている考え方を紹介したいと思います。ビッグデータを読み込み、やみくもに可視化しても、有益な結果を得ることが難しいと思われます。つまり指針になるものが必要だと思います。例えば、航海をするときは、コンパスや海図などがないと目的地には行けないことと似ています。データ解析の場合には、要約や可視化という手段で、探索的にデータの持っている知見や情報を引き出して、それに基づいてモデリングを行ってフィッティングをして、さらに、それを診断する工程が必要な指針になります。そして、その工程のサイクルを回すことによって、モデルをより精度の高いものに持っていき、最終的に推測や意思決定につなげる。このような解釈に基づいて、われわれは日々データ解析を行っています(図2)。

現在では、「データサイエンス」(data science)という言葉が、世間的にほぼ定着したと思います。それにともなって、データサイエンスに関するテキストが何冊も出版されています。例えば、Bruceらの『Practical Statistics for Data Scientists』は良書であり、探索的データ解析の重要性についても言及されています。われわれはRを利用してデータサイエンスを実行しており、この意味で重要なテキスト『R for Data Science 』の第2版をよく参照します。この筆頭著者のHadley Wickham氏は、データサイエンスを実行する上で非常に重要なR のパッケージ群 (tidyverse) や、統合開発環境である「RStudio」の開発の中心人物です。この書籍の第10章に「Exploratory Data Analysis」(探索的データ解析) についての言及があります。このように約50年前に提唱されたリサーチメソッドですが、現在でも色あせず、実際に、われわれの研究スタイルに指針を与えてくれています。ちなみに、Hadley Wickham氏の指導教官はDi Cook先生であり、私の同僚であり共同研究者の阪先生(関西学院大学)は在外研究としてCook 先生のもとに訪問され、共同研究を行っていました。
コンピュータ環境
私はこれまでにデータ解析のためにどのような環境が適しているかを模索してきましたが、現在どんな環境を利用してデータ解析を行っているかを、紹介したいと思います。環境は、大きく分けて、クラウド環境とローカル環境があります。まず、クラウド環境としては、2022年から、東京大学柏第Ⅱキャンパスの「mdx」という環境を利用しています。なお、大阪大学の吹田キャンパスにあるサイバーメディアセンターが最近改組されてD3センターになり、そこに2番目のmdx環境 (mdx II) が整備されたため、2024年の9月頃から東京大学のmdx環境は「mdxⅠ」と呼ばれるようになりました。このmdx環境は最近ChatGPTに代表される大規模言語モデル(Large Language Model: LLM) の日本語版となるシステムを構築するために基盤となる環境として注目されています。mdxⅠという環境は、一般に、「IaaS」(Infrastructure as a Service)と呼ばれるクラウド環境の1つで、コンピュータシステムの構築や稼動させるための基盤を、インターネット経由のサービスとして提供する環境のことです。インフラの部分のみレンタルされ、「オペレーティングシステム」(Operating System: OS)より上位のシステムを各自で自由にインストールすることが可能であるような仮想環境です。仮想環境なので、1台1台、実機があるわけではなくて「ノード」(node) という単位でレンタルされます。われわれが利用している環境は、ログインのために1ノードとGPU環境を1ノード、CPUを3ノードの合計5ノードをレンタルしています。特徴的なのは、GPUノードには「A100」というNVIDIA製のGPGPUが搭載されており、非常に多くのGPUコアをもっています。なお、CPUノードも、1ノードあたり152個のコアがあるのも特徴です。
柏第Ⅱキャンパスに敷設されているmdxは、富岳と同様に富士通による設備です。現在、mdxを利用して、国立情報学研究所の所長である黒橋先生が中心となって、日本語版の大規模言語モデルを構築するプロジェクトが進行されています。このことからも、mdxはさまざまな人たちが共同利用するプラットフォームになりつつあるということです。
ローカル環境は、CPUコアが多く搭載されたサーバーPCとMac環境です。Mac 環境には、機動性を重視したノートPCであるMacBook Proを利用し、また、デスクトップ環境は、Mac Studioを利用しています。両環境とも、メモリを128GB、ストレージが8TBというのがポイントです。常にPCのパワーを最大限に使って処理することを試みています。ローカル環境でテストベッドを作って、クラウドのmdx環境を使って高速に処理するような連携仕様で研究を続けています。
再現可能研究
われわれは、「再現可能研究」 (reproducible research) にも取り組んでいます。これは、分析・解析の結果を、再度得ることができるかという視点で研究を行うということです。私が、大学院生のときには、論文を作成するときに、図や表等の解析結果を、データ解析ソフトから文書作成ソフトに手作業でコピー・アンド・ペーストしていました。このような論文作成のスタイルが再現可能かどうかということについて、2011年にRoger D. PengによってScience誌上で提案された「再現可能性のスペクトル」(reproducibility spectrum) に照らすと、全く再現可能ではないということがわかりました。このスペクトルでは、「公開されただけのもの」 (Publication only) は、「再現可能ではない」(Not reproducible) と明記されています。一方、「完全に再現できる場合」 (Full replication) は、「ゴールドスタンダード」 (Gold standard) というレベルになります。このスペクトルに照らして、ゴールドスタンダードの領域で研究できるための方法にも取り組んでいます。
ソフトウェア環境
データの前処理や解析、論文作成の全工程を再現可能なものにするためのOS のセットアップとソフトウェア環境を、列挙したものを与えます(図3)。mdx環境を使うときもそうですが、OSはWindowsではなく、「Unix系OS」を使っています。macOSもBSD(Berkeley Software Distribution)OSをベースとしたUnix OSですし、Ubuntu はDebian 系 Linux、RockyはRedHat系Linuxです。Unix系OS上で「シェル」(shell)や「コマンド」(command) 等のさまざまなツール群を利用して、データの前処理などを実現しています。また、Rとデータベース管理システムである「PostgreSQL」を連動させて全体の環境を構築しています。Unix系OSを利用している理由の1つとしては、元来この環境がシステム開発をするための環境として構築されてきたということによります。

データ解析を行う環境はシステム開発を行うためのそれと本質的によく似ていると思います。よって、親和性が非常に高いわけです。特に「make」というコマンドを利用するために、Unix系OSを使っているといっても過言ではないと思います。なお、現在利用しているクラウド環境にアクセスするためには、基本的にはUnixのコマンドラインから「ssh」コマンドを利用して接続します。接続後は、リモートのUnix環境上でコマンドラインから操作するという仕様です。このようなことからも、必然的にOSはUnix系が選択されます。なお、よく人から「Windowsでは駄目ですか?」と聞かれます。もともと私も20年来のThinkPadファンでしたが、Windows上でデータベースを構築するためにmakeコマンドを利用しようとしたのですが、ファイルシステムとの親和性を確保できないために諦めたという経緯があります。
昔、MS-DOSのAUTOEXEC.BATのようなバッチファイルがありましたが、makeはバッチファイルを使った処理を行うためのツールの高機能なものと考えることができ、Unix上で処理を自動実行するために利用されます。処理を行う工程をスクリプトとして記述し、makeコマンドを実行することによって、自動実行させます。自動実行することによって、人の手をできるだけ介さないため、再現性も確保できます。
また、皆さんの中には、テキストファイルやCSVファイルなどのデータを扱われる方も多いのではないでしょうか。ただし、ギガ単位のCSVファイルを処理するためには、通常のエディタやExcelでは読み込むことが難しいと思います。ちなみに、Excel では最大100万行程度しか読み込めません。われわれが扱っているデータは、中規模のものでも約300万行あり、Excelで読み込めないので、Unixコマンドを使って処理します。さらに、CPUコアを全て使って処理する方が効率的であるため、「GNU parallel」というツールを使って実現しています。また、そういう大きい(重い)データを「列指向型」 (columnar storage) のファイル形式で扱うということが最近標準になっていて、「Parquet」(パルケ(イ)またはパーケイ)と呼ばれる形式を利用しています。
さらに、データファイルが100ギガを超えてくると、このままでは大きすぎて処理できないものがあります。そのときには、PostgreSQLでデータベース化する必要があります。さらに、データベース化したものから、単純にデータを抽出しようとすると、かなりの時間がかかります。それを、「GPGPU」というグラフィックボードに搭載されたユニットを使って高速化する「PG-Strom」というツールを開発している海外浩平さんという日本人の開発者がいらっしゃって、そのユニットを使ってデータを高速に抽出することを実現しています。なお、海外さんのグループとは現在、共同研究を行っています。
一方、J. W. Tukeyが提唱した探索的データ解析を実行する環境をデザインしたのが当時米国ベル研究所のJ. M. Chambersです。そのデザインの名称が「S」と呼ばれています。さらに、そのデザインの元に、コンピュータ言語として実装されたものが「Sシステム」、後に「S言語」と呼ばれるものです。また、同じコンセプトと設計で作られて(別)実装されたものが「R言語」です。探索的データ解析を実行できる環境として作られているので、親和性は高いです。われわれがRを使う理由はそういうところにあります。
最近、「Python」を使う人もいますが、Pythonは、情報科学者が情報科学者のために作った言語といわれています。Rは、統計(科)学者が統計(科)学者のために作った言語といわれており、このことは非常に本質的です。私もPythonを使うこともありますが、Rが、探索的データ解析を行うためには、私には合っていると思います。
私はRを強化するデスクトップ環境のRStudioも使って分析・解析を行っています。パッケージはtidyverse等を使ったり、可視化については「GGally」パッケージを使ったり、インタラクティブな可視化を実現するためには「plotly」も使っています。再現性を実現するためには、「Sweave」等のツールを利用しています。
世界の上場企業の探索的データ解析
それでは、われわれが取り組んでいるテーマについて紹介したいと思います。ファーストチャレンジは、世界中のほぼすべての上場企業の情報が収録されている「Osiris」というデータベースから抽出されたデータです。ベンダーに、このデータベースからその時点で取れる分だけ抽出してもらったデータを分析しています。再現性も考えて、組織立ったディレクトリにファイルを配置してデータ解析を行っています(図4)。
Osirisには、年ごとにバージョン番号が付与されています。ここでは、2020年のバージョンから抽出されたデータセットのファイルを処理するプロセスについて紹介します。一般に、「データの前処理には、データ解析の全工程のうちの50~90%の労力が費やされる」という経験則があります。データ解析の全体の工程の中には、論文執筆等の時間がかかりそうなパートも含まれますが、私の経験では前処理に90%ぐらいの労力が費やされたと感じています。そのため、この前処理をいかに効率的に行うかが重要だと思います。Osirisは、2020年時点で96,377社の世界上場企業のデータが収められていました。なお、もともとOsirisはBureau van Dijk社が販売・運用していましたが、Moody's社と合併したので、現在はMoody's社のデータベースになります。

抽出していただいたOsirisデータは、上場企業の30年分のパネルデータ(同一の対象を継続的に記録したデータ)を集約したものです。さまざまな税に関する情報もあります。企業情報や会計情報など、91系列のデータをベンダーに抽出してもらいました(図5 )。

搬入された粗データは1.6GBで、約300万行でした。このようなデータを処理するようになった最初の頃は、この規模のものでも「扱いが大変だ」と思っていました。また、データの構造がヘッダーパートとデータパートにわかれていて、この処理にもかなり悩まされました。データは、96,377社分のヘッダー行と30年分 (30行) のデータ行が繰り返しあらわれる仕様です。企業名はヘッダー行にしか入っていないので、ヘッダーから企業名を切り取って、データを作り変えないといけません。しかし、データ行の1行目には不要なコードが入っていたりするなど、これらの処理を考えると、頭が痛くなるような状況でした。さらに、金額のカンマをどう扱えばいいのかとか、欠測値コードがない欠測値があるなど、これらの問題を手探りで見つけて対処していました。これまでに約10年間、前処理と向き合っていることから、今ではある程度経験も積みましたが、当初は本当にどうしたらいいか試行錯誤を繰り返しました。Unix コマンドのgrepやインタープリタのsedなどを利用して置換するなど、地味な作業を繰り返すことによって、なんとか前処理を行うための手順を見つけることができました。なお、各処理を一つひとつ手作業で行う方法は、人為的なミスが起こる可能性があるため、全処理工程を実現するためのスクリプトを作成し、makeコマンドを実行することによって自動実行することによって、処理を再現する方法を確立することができました。
以上の工程を、特別なツールを用いないで MacBook Pro 2021で実行すると2分33秒かかりました。そこで、GNU parallelを使ってCPUコアを全部使って処理するようにスクリプトを修正し、自動実行することによって、処理にかかる時間が5分の1に短縮できました。
前処理が終わってデータが読み込めたら、すぐデータ解析ができるというわけではありません。例えば、業種を表すSICコード(Standard Industrial Code)が各企業の30年分のデータの最初の行にしか掲載されておらず、残りの29行には全部欠測しています。もともとのデータベースの構造上仕方ないのですが、このような問題をどう処理すればよいかという更なる困難がありました。また、他にも、同名企業が存在し、企業名ではデータを一意化できないということも問題となりました。
このような問題を処理するための強力なツールが、「dplyr」というRのパッケージです。dplyrには、さまざまなツール(関数)が用意されていて、処理時間も高速です。例えば、税の情報は企業から見たらマイナスですが、分析するときにはプラスに変更しないといけません。dplyrの「mutate」関数を使うことによって、このような地味な作業を、文法的に統一感をもって処理することができます。「lubridate」パッケージに付属する関数を利用すれば、日付情報も分析・解析できる専用のオブジェクト形式に変換して扱うことができます。このような処理をすべて行い、最終的にCSVファイルとParquetファイルとして出力するようにRでコーディングしました。この工程は、実行時間が30秒ぐらいで終わります。処理されたファイルも約1.5GBのCSVファイルでした。また、同じ内容のデータをParquetファイルに出力すると7分の1ぐらいのサイズになり、この形式のものの方が、処理後の扱いは格段によくなります。
このような前処理とラングリングの工程をすべて一括で行うスクリプトをMakefileに記述しておき、makeコマンドを実行することによって、一括処理できるようにしました。処理にかかる時間は1分3秒まで短縮できました。
ここからは探索的データ解析についてお話しします。探索的データ解析では、データを読み込んで可視化する工程があります。可視化のために「ggplot2」というパッケージを使用します。ggplot2 の頭文字の‟gg”は、L. Wilkinsonが著書『The Grammar of Graphics』で提唱した、グラフィックスを作成するための文法を意味する‟Grammar of Graphics”の頭文字です。なお、ggplot2は、「レイヤー構造」を扱えることも特徴の一つです。
これ(図6)は、売上高のヒストグラムを描いたものです。左図は粗データ、右側は歪みを解消するために対数(log)を取ってから描いたものです。このような結果を論文として投稿すると、左図のようなものは、「この可視化は理解できない」といわれます。データの歪みが大きいだけなのですが、このような過度の歪みを見たことがない人にとっては、理解できないようです。一般に、歪みを解消するためには対数変換が常套手段です。右図からもわかるように、ほぼ正規分布に近くなります。しかし、よく見ると少しだけ左側に歪んでいることがわかります。この歪みをどう扱えばよいかを、いろいろ考えていました。正規分布に従っているかどうかは、正規Q-Q プロットを描くことが標準的な可視化の方法です(図7 )。この結果から、裾(テール)の部分が合っていないことがわかり、正規分布に従っていないことがわかりました。以上の可視化の結果から得られた知見は、売上高は対数を取っても正規分布にならないということでした。この問題に対処するために、「sn」 (Skew-Normal) というRパッケージをモデリングに利用しました。


Azzaliniという数理統計学者が、1985年の論文[1]で正規分布に少しだけ歪みを持たせるアイデアを紹介します。その結果が40年の歳月を経て発展してきました(図8)。私が財務諸表などの会計データを扱うようになってから、現象をモデリングするためには、「正規分布」(normal distribution)だけでは無理だと思っていました。ただし、正規分布に非常に似通っている部分もあるが、裾の部分がモデルで追えないところがあるという現象をどのようにモデリングすればよいかを模索している中で、「非対称正規分布(歪正規分布)」(skew-normal distribution) に出会いました。正規分布に、ある種の関数(累積分布関数)をかけることによって歪みをもたせます。そうすると、正規分布に近いけれど右に歪んでいるとか、左に歪む分布を作ることができます。売上高の対数を取ったものに対して、非対称正規分布を当てはめるということは、非常に意味があるのではないかということを2017~18年の研究で気づきました(図9)。数理統計学的なインプリケーションなのかもしれませんが、非対称正規分布と、さらに少し裾が重い場合には、「t分布」(t distribution) に歪みをもたせた「非対称t分布」(skew-t distribution) を当てはめてみたら、よりよく当てはまる場合もありました(図10 )。これらの知見をもとに、回帰モデルもモデリングできないか検討したことを紹介したいと思います。



ここまでは、売上高だけのモデリングでしたが、Cobb-Daglas型の生産関数を利用して従業員数、資産合計によって売上高をモデリングができるのではないかと考えました。さらに、誤差構造を正規分布だけでなく、非対称正規誤差や非対称t誤差を考慮してモデリングしてみました(図11・12)。
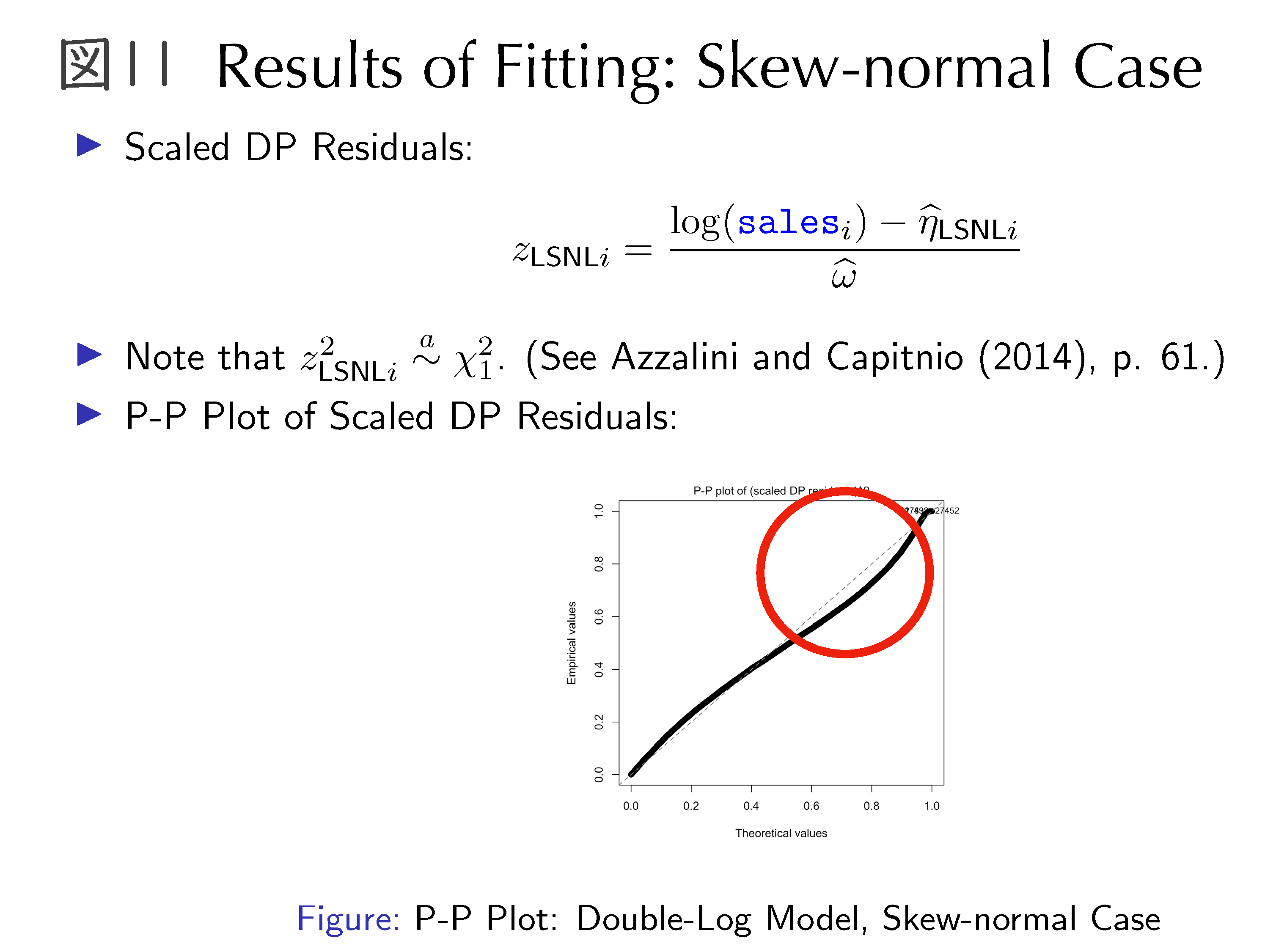 まず、正規誤差を仮定して当てはめてみたところ、残差の可視化の結果として誤差分布が正規ではないことが明確になったため、非対称正規誤差をもつモデルを当てはめてみました(図11)。しかし、残差のP-Pプロットの結果はあまり良くなかったので、非対称t誤差をもつモデルを当てはめたところ非常によいことがわかりました(図12)。この結果は、2018年にJapanese Journal of Statistics and Data Science (JJSD)誌に掲載されました。探索的データ解析を行うことによって、数理的にも非常にきれいな構造を持っているという知見が得られた一例です。回帰平面を描くと、このようになります(図13)。
まず、正規誤差を仮定して当てはめてみたところ、残差の可視化の結果として誤差分布が正規ではないことが明確になったため、非対称正規誤差をもつモデルを当てはめてみました(図11)。しかし、残差のP-Pプロットの結果はあまり良くなかったので、非対称t誤差をもつモデルを当てはめたところ非常によいことがわかりました(図12)。この結果は、2018年にJapanese Journal of Statistics and Data Science (JJSD)誌に掲載されました。探索的データ解析を行うことによって、数理的にも非常にきれいな構造を持っているという知見が得られた一例です。回帰平面を描くと、このようになります(図13)。


動的文書生成と再現可能性
データ解析の結果を文書化する際に、再現可能性を担保して作成するための環境としてどのようなものが適切かを考えてみます。通常は、データ解析フローとドキュメントを作るフローは、パラレルに流れています(図14)。マニュアル操作でデータの一部を貼り付けたり、結果の一部分をドキュメントに貼り付けて文章を作ったりすることが普通だと思います。しかし、マニュアル操作は基本的には手作業ですので、後日、どのように作成したかわからなくなることがありました。また、マニュアル操作で作成した論文は、データが少し変わっただけで図表などを全部貼り付け直す作業が発生します。
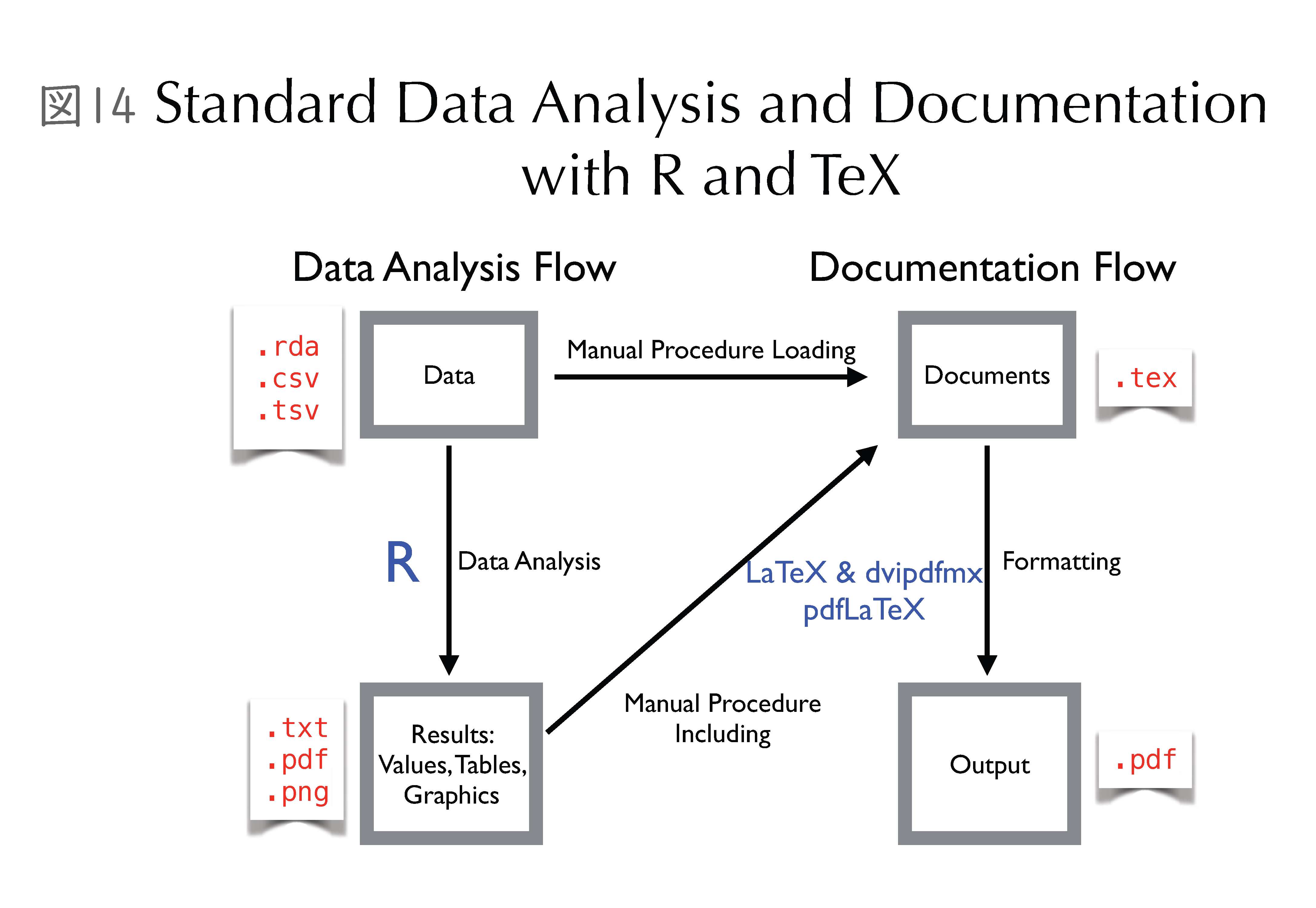
「Dynamic Documents」という言葉が、この10年ぐらい前から聞かれるようになりました(図15)。これは、「動的文書生成」などと訳されます。この言葉が意味するところは、文書ファイルにRなどのコードを埋め込み、自動的にデータを読み込んで、その分析・解析結果の図表などを自動的に生成し、それらの結果を自動的に再度読み込んで、最終的に文書を作るということです。例えば、Sweaveというツールがあります。データを用意して、「Rnw (R noweb) ファイル」を用意します。R, Sweave, LaTeXシステムを併用することによって、データを読み込んで解析し、その結果を文書ファイルに読み込み、LaTeXでコンパイルして、文章を生成するという工程を自動化できます。ドキュメントを自動的に作ることができるのが、非常に重要なポイントです。

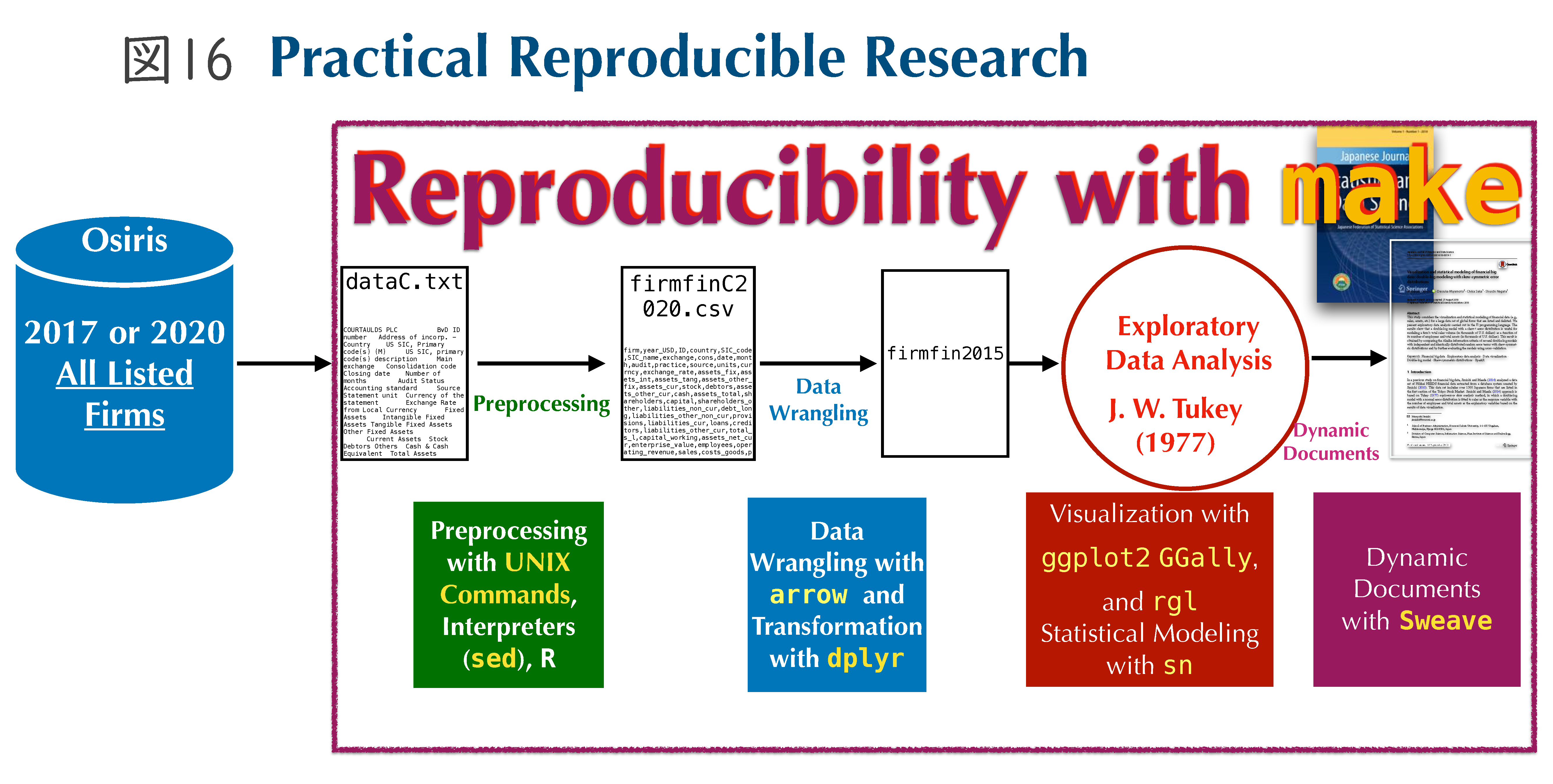
例えば、JJSDへ掲載された論文は、入稿段階までのファイルは全部、動的文書生成環境で作りました(図 16)。最終的に手直しされるところは、Reproducibleではないかもしれませんが、入稿段階までのものは動的文書として作成しました。JJSDに掲載された論文は、前処理から始まって、データを読み込んで分析して、論文として最終的にPDF化するという全工程を、makeコマンドを実行するだけで再度完全に作成できますので、Roger D. Pengによって提案された「再現可能性のスペクトル」において、‟Full replication”となり、‟Gold standard” の研究といえるのではないかと思います。なお、この全処理工程は、4分36秒で実行可能でした。
また、拙著[2] を出版した際に、出版社に入稿する前の原稿は自動生成するようにしました。
このように、論文や書籍を執筆する際に、データの前処理・ラングリングから論文ファイル生成までの全工程を処理するスクリプトをMakefile で管理して、makeコマンドで自動実行することによって作成するような仕様としておけば、再現性が確保できますので、作業時間はそれなりにかかりますが、通常のデータ解析を手作業で行って論文や書籍を作成する場合よりも、再現性についてより高い安心感を得ることができます。
世界の非上場企業の探索的データ解析
では、次により大きな財務データを扱っていることについて紹介したいと思います。われわれは、世界中の企業2,600万社のデータを前処理しラングリングしたものを、可視化した結果から、どのような知見を得ることができるのかという研究を、ここ10年ほど並行してやってきました。抽出した2019年当時のデータは、約3億社のデータがありました。その中からベンダーと相談して2,635万社のデータを連結主体と単独主体でそれぞれ抽出し、2種類のデータセットを処理しました。
このような規模になるとCPUコアが多く搭載されている環境でないと処理できません。まずは、テストベッドのスクリプトを作って処理しました。データセットの規模としては142GB、約3億行ありますが、上場企業の場合と同様のデータ構造なので、基本的には同じような処理をすればいいわけです。しかしながら、2GBなら短時間でできていたことも、約5GBのファイルが27個もあると、規模がボトルネックになって処理を短時間行うことが難しくなります。そこで、GNU parallelを複数回の工程で利用して処理するようにしました。ローカル環境では、6時間以上かかっていた工程が、GNU parallelを利用することによって1時間30分ぐらいで処理できるようになりました。
できあがったデータは、連結・単独それぞれについて1つのCSVファイルに連結しました。このあたりの工程は、2020年ぐらいまでに確立した技術です。さらに、2023年度にmdx環境で処理を行ったところ、CPUコアが152個あることから、全体の工程を30分短縮することができました。この処理を行っているときに、mdx環境全体に影響を及ぼしてしまうようなトラブルに見舞われたりしました。しかしながら、このトラブルにより、mdxに内在する根本的な問題があることがわかり、解決に至ったことを知りました。まさに、「テストドライバー」のような役割を担うことができたことは光栄でした。さらに、2024年度は、152個のCPUコアを3ノード並列で動かすことによって、処理時間は約3分の1になりました。まさにスケールアウトの効果があったといえると思います(図17)。

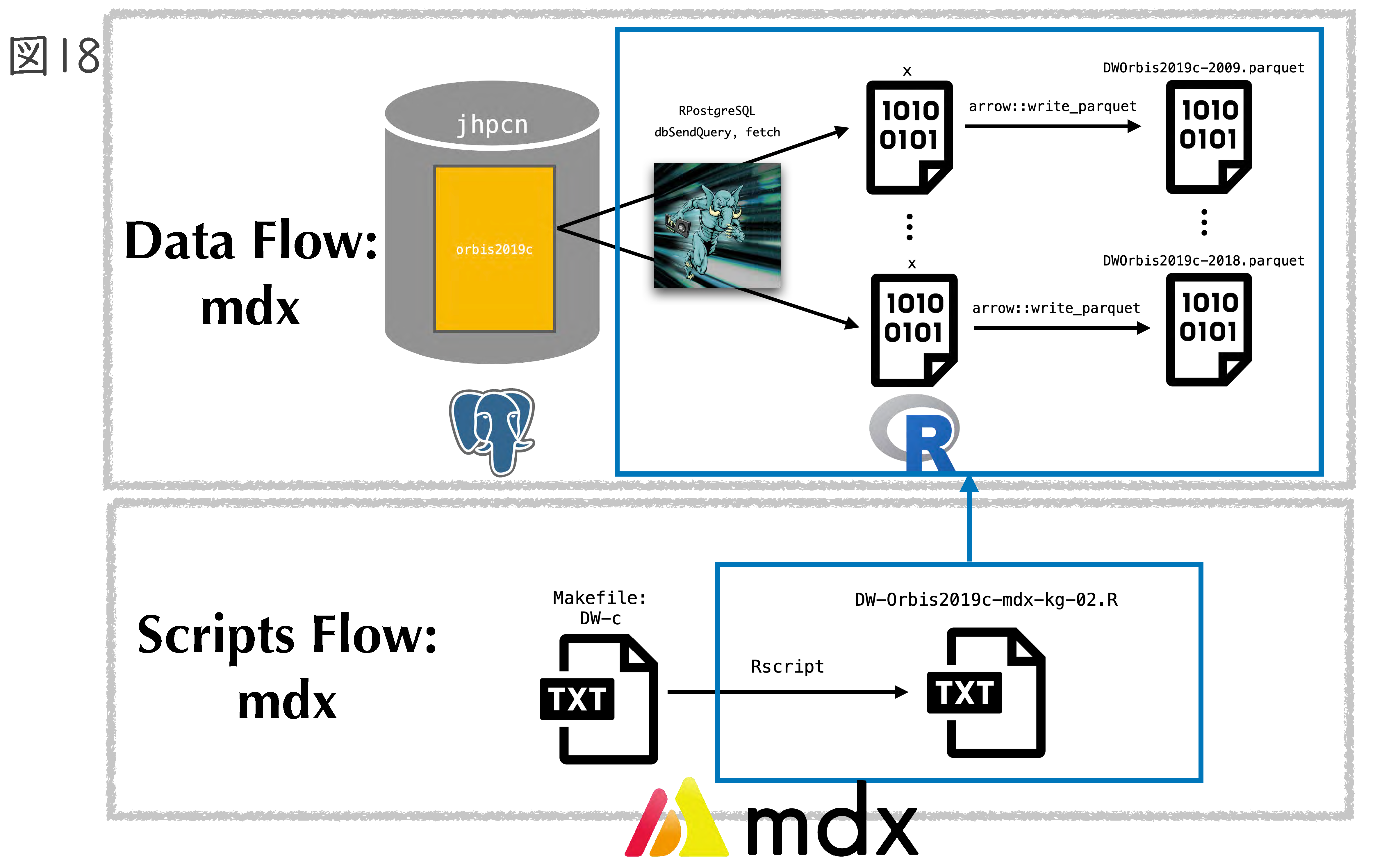
前処理は、ほぼ技術が確立できたと思っています。あとは前処理したものから、必要なデータを抽出して解析する工程ですが、142 GBのファイルを直接Rに読み込むことは難しいため、データベース化しています。ただ、データベースからデータ抽出するだけでも、かなりの時間がかかります。その抽出作業を、mdx のNVIDIA 製のGPU環境のもとでPG-Stromを使って高速化できないかトライしてみましたが、2022年の作業では、チューニングが難しく、4時間18分かかりました。これでは探索的データ解析はできません。そこで、阪先生と宮本先生とともに研究グループを立ち上げ、PG-Stromの開発者である海外浩平さんにも入ってもらい共同研究を行うことになりました。その結果として、チューニングが成功し、6分(4時間以上短縮!)で処理できました(図 18)。GPU環境をうまく利用すれば高速に処理が可能であるという典型的な例ではないかと思われます。また、可視化もmdxのCPUノードを並列で処理したところ、非常に短時間でできるようになりました。
最後に、現在、鈴木先生が代表となる科研プロジェクトの研究課題として、Apple Vision Proを使ってインタラクティブ性を持つような3Dの仮想空間上への可視化に取り組んでいます。
[1] A. Azzalini, ‟A class of distributions which Includes the normal ones”, Scandinavian Journal of Statistics, Vol. 12, No. 2 (1985), pp. 171-178.
[2] 地道正行,『データサイエンスの基礎 Rによる統計学独習』, 裳華房, 2018.
パネルディスカッション
<パネリスト> 村上 裕太郎氏、安間 陽加、地道 正行氏

<モデレータ> 鈴木 一水(神戸大学大学院経営学研究科 教授)
補足説明
鈴木 3人の先生方にはかなり詳しくそれぞれの研究について紹介いただきましたが、補足があるということですので、村上先生からお願いします。
村上 EBPMに資する税務研究で、なぜ主体の行動原理を考える必要性があるのか。理論研究や分析的研究は、なぜ主体はそういう行動をするのかを考えましょう、という目的でやっています。それがなぜ大事なのか、私がよく使う例でお話しします。

図Ⅰ
例えば、図Ⅰ左の赤いところに、とあるゴルファーが打ったボールが転がっていると思ってください。このデータだけを見てコーチングしてくださいと言われたら、どのように指導するでしょうか。おそらく、このゴルファーは普段はまっすぐにボールを飛ばせるのに、たまに左に引っ掛けて(フックして)しまうと判断するのが自然でしょう。すると、処方箋としてはフック(左に曲がる)を矯正しようとするはずです。ただ、実際は全く異なっています。このゴルファーはスライス(ボールが右に曲がる)に悩んでいるのです。練習場でスライスが直らないため、ゴルフ場では左の方を向いてボールを打っているのです(右図参照)。左の方を向いてスライスをするので、ちょうどボールがフェアウェイ中央に落ちているのですが、たまにこの人もボールがまっすぐに飛びます。左に向いてまっすぐ飛んだボールが、フックしたと思われていたものです。つまり、このゴルファーはスライスで悩んでいるのに、データだけを見た人は、この人はフックで悩んでいると勘違いしてしまうのです。これが行動原理を考えることの重要性です。
実証研究では、さまざまなデータが使えるようになり、統計ソフトも優れたものを誰でも使えます。こういう時代でも、行動原理を考えることは大切です。経済学者の方々に対しては、釈迦に説法かもしれませんが、ルーカス批判の話をさせてください。ルーカス批判は、どんなに精緻な統計、構造方程式でパラメータを推計したとしても、そのパラメータ自体が政策変更によって変化してしまうという指摘です。そうすると、過去推計したパラメータを用いて将来予測を行ったところで、パラメータ自体が変化しているわけですから、全く意味のない、むしろ間違った処方箋や政策提案をしてしまう可能性があります。最近は、会計研究の中でも構造推定といわれる政策変更によって影響を受けないディープパラメータ(時間選好率や個人の選好など)を推計する研究が、少しずつ出てきています。税務の世界でも、構造推定を用いた研究がThe Accounting Review誌に掲載されました(McClure, 2023[i])。
実効税率を見て租税回避といわれることがありますが、実際に租税回避目的で実効税率が下がっているかどうかはよくわかりません。実証では、租税回避目的以外の要因をできる限りコントロールしようとしますが、それにも限界があります。ですから、モデルから実証分析に資するような貢献ができるかどうかが理論研究の重要な役割となっています。
EBPMを考えるときに行動原理が大切だ、というのは、このような理屈によるものです。補足は以上です。
鈴木 引き続き、地道先生にお願いします。
地道 mdxはさまざまな分野で利用されており、Webページ(https://mdx.jp/mdx1/p/doc/cases)で、さまざまな利用事例が紹介されています。ケース1として、LLMの大規模言語モデルをmdx上で作るプロジェクト、ケース2として、阪先生と私も取材を受けました。ご一読いただければ、私たちが取り組んでいる問題についてご理解いただけると思います。是非、ご参照ください。
鈴木 では、どの報告者に対してでも結構ですので、何かご質問のある方はお願いします。
所得拡大促進税制適用企業について
質問者1 安間先生に質問ですが、実際に要件を満たしている企業を集めてこられて、どんな企業が要件を満たすような賃上げをされていたのか、というのを教えていただきたいと思います。
安間 今回は限界税率に着目しましたが、以前、成長性や収益性など、基本的な財務状態、財政状態について、企業特性という観点から分析を行いました。今回はそれをコントロール変数という形でモデルに入れております。基本的には収益性が高いとか成長性が上昇傾向にある企業が、この制度を利用する確率が上がるという検証結果が出ています。
損金不算入のモデル
鈴木 私から村上先生のモデルの設定のところを教えていただきたいのですが、課税所得の計算式のところで、δをかけているeは努力、ηは何でしょうか(村上氏講演録 図1)。
村上 それは、誤差項がないと、努力水準が株主から観察できて、ファーストベストの(株主にとって望ましい)努力水準を強制させることができるので、どれだけ経営者が頑張っているか株主から観察できないというのが、モラルハザードでは必要です。例えば、経営者は接待交際活動にどれほど従事しているかはわかりませんが、誤差項がついた交際費という形で株主は観察することができます。
鈴木 情報の非対称性があるということですね。
村上 期待値をとれば、誤差項部分は0です。
鈴木 とすると、wは決まって、νがeffortで決まるのはわかりますが、δをなぜ(e+η)側にかけるんですか。例えばwにかけてもいいわけですよね。
村上 報酬(w)の一部が損金不算入になるのであればそれでOKですが、今回、報酬は全部損金算入されるという設定です。交際費以外は損金算入、つまり、交際費だけが損金不算入となっています。これは、課税所得のzから引くときに、ν-wは引かれるので、損金不算入部分(δ)がなければ普通の1-tでくくれるような形になります。
鈴木 例えば、過大給与の損金不算入とか、役員賞与にも当てはまりますね。
村上 そうですね。もし過大役員報酬の損金不算入制度をモデル化するのであれば、wにδをかけるようなモデル設定が必要です。
鈴木 交際費だけを想定しているということになると、飲食やゴルフに行くのが好きな人がいるから、その分だけプラスになるのはわかりますが、eの関数になるのがよくわかりません。
村上 例えば、接待交際活動の時間が増えれば増えるほど、この人はうれしいと考える。時間で考えるとわかりやすいと思います。
鈴木 なるほど。必ずしも心理的な犠牲ではないということですね。
村上 交際活動eからγeの部分の心理的なベネフィットを得て、c e²/2の心理的コストを負担しているという設定です。
鈴木 このモデルは、あくまで経営者とか従業員にとって利益となるような費用の損金不算入ということですね。
村上 そうです。ただ、消費財的性質の度合いを表すγは0も許容していますので、γが0でも成り立ちます。
鈴木 0だったら、自分の損で、その分だけ企業価値が増加する話になっています。経営者が、私的利益を会社から支出する場合はどうでしょうか。
村上 それは売上貢献のaがすごく小さくなります。
鈴木 私的利益が少なくても、aで見たらいいということですね。
村上 そうすると全く会社に貢献をしないゴルフや飲食活動をしているということになります。費やしたとしても本人だけがうれしくて、利益には全く貢献していないということです。
給与の損金算入の話は、ルーカス批判とつながりがあるので説明しておくと、アメリカで役員の報酬が高すぎるということで、100万ドルの上限が設けられましたが、固定給のみ損金不算入なので変動給にシフトしました。結果的には、アメリカ企業の業績が高くなったことで株価は上がっているので役員報酬がさらに増えて、トランプ政権になってから、変動給でも固定給でもどちらでも100万ドルを超えた部分の報酬が損金不算入となる制度に変わっています。
鈴木 役員給与は、日本でも不相当に高額な給与については損金不算入ということになっています。しかし、ミリオンダラーといった明確な基準があるわけではなくて、課税庁の裁量で不相当に高額か適正かに決めてしまうわけです。その辺は、内生性がありそうな気がしますが、現実問題として何かの変数の影響を受けてということではなくて、そのときの気分で決まっているのではないかと思います。その辺に対して村上先生の研究をアピールしていただいて、行き当たりばったりではなく、損金不算入はやめてほしいと思っています。それもEBPMに向けた研究の1つの貢献だと思います。
損金不算入契約研究の戦略策定・政策立案への含意
鈴木 では、このワークショップのメインテーマになってきますが、登壇いただいた先生方の研究成果がEBPMにどのように貢献、あるいは含意を提供できているかについて、政府の制度設計のみならず、企業の戦略策定、できれば両方に対して、何を提供できるのかということをお話ししていただきます。
村上 例えば、先ほどの鈴木先生のお話でいくと、政府側が損金算入割合を決めるときに、場当たり的に決めているのではないか、ということでした。損金不算入割合を内生化したときのモデルの比較静学の結果、政府が何を最大化するかというのはすごく難しい問題で、一般的に多いのが社会厚生です。今回は税収最大化を目的とする政府ということで、もし税収最大化を目的とするのであれば、他の法人税率や生産性、あるいは費目に応じて損金不算入割合(δ)を柔軟に変えていく必要があるというのが1つの提案、提言です。
鈴木 モデルに限定しなくてもいいのですが、制度設計とは別に、企業の経営者報酬体系の設計、あるいは交際費をどのくらい使うかなど、企業経営面で何かインプリケーションはありますか。
村上 働きがいはすごく大事だと思いますが、フリンジ・ベネフィットのような非金銭的なインセンティブで働くことができる人を確保できれば、従業員が辞めなくて済むし、報酬を低く抑えることができるというのが、一般的なフリンジ・ベネフィットの研究の共通の結果です。今回の研究ですと、接待交際費が有力なインセンティブとして使うことができるので、企業としても、生産性が担保できるのであれば、積極的に使っていく価値があるのではないかと考えています。
鈴木 今のお話は、村上先生の講演資料の「実証含意②」についてだと思いますが、「実証含意①」の法人税率で、税率がインセンティブ率と経営者の努力水準に与える影響は、損金不算入割合の大きさに依存するという、これも経営判断としては役立つ情報です。不相当に高額な役員給与の損金不算入のような不確定概念になるとリスクがあるから、はっきりわかりませんが、例えば、交際費などでは、損金不算入割合はわかっているわけです。そういう場合、交際費の損金不算入割合を見ながら、経営者や従業員の努力をいかに引き出すか、という交際費の使い方も考えるといいのではないかと思います。
交際費の損金不算入制限は緩和していますが、むしろその枠を使い切っていない会社が多いです。それはなぜかと企業経営者に聞くと、交際費の使い方がわからない経営者が結構いるようです。損金不算入が緩和されても、特に飲食費は使い切れていないという意味で、政策効果がほとんど実現していません。みんなで飲みに行って、企業業績を上げて、税金を払いましょうという方向に向かうといいのではないかと思っています。
村上 今のお話で、損金不算入割合(δ)は何割ぐらい不算入になるか、というモデルではそういう設計の仕方です。各国の不算入規定を調べると、1つは何割までOKという金額もありますが、もう1つは範囲です。どこまでを交際費とみなすか、ということです。例えば、アメリカは厳しくなってきていて、スポーツ観戦もアウトで全額損金不算入です。接待でスポーツ観戦に行って、そこでホットドックなどを買って飲食した場合どうか、といった難しい問題があります。飲食はOKですが、ゴルフとかスポーツ観戦は駄目というように、どの接待行為を損金不算入にするかはすごく重要だと思いました。
鈴木 それはフリンジ・ベネフィットでも同じことが言えます。
所得拡大・研究開発促進税制研究の戦略策定・政策立案への含意
安間 私からは、まず日本の課税優遇措置に関してお話しします。今回は所得拡大促進税制に着目しましたが、同じような制度が名前を変えるだけで毎年のように施行されている状況が常態化しています。これは所得拡大、賃上げ税制に限った話ではなくて、設備投資や研究開発投資に関するものが、毎年同じような税制として施行されています。実際のところ本当にそれが政策の意図した通りに機能しているかどうかに関しては、きちんとした検証がなされていない現状です。闇雲に時限立法で期限が来たから名前を変えようとか、税額控除の割合を変えるのではなく、この程度の割合ならばこれだけの効果があるとか、このぐらいの割合だと企業は動かないとか、そういった検証をしっかりとしていく必要があると考えています。
今回は投資が増加したかに関して検証したものではありませんが、制度改正に関するインプリケーションは提供できるのではないかと考えています。
鈴木 これも、政府の政策立案に対するインプリケーションですね。企業経営で何かありますか。
安間 企業経営に関しては、今回、伏在税という形で議論させていただきました。こういった制度を利用することで、確かにその制度が予定した通り、ETR、税金は確実に下がっているのではないか、という知見が得られています。おそらく企業もそれを狙って利用しているわけですし、非常に良い点ではあるのですが、果たしてそれが企業の税引前の利益にどういう影響を与えているか、税引後のキャッシュフローを最大化させる形で意思決定を行っているか、に関してまでは、企業内でもどこまで議論ができているか定かではない、という問題点があると思います。
利用している企業の税引前の利益が一定程度低下していることが明らかとなっているように、さまざまな課題がありますが、そういった結果を一定程度示したということもあります。企業が人件費としての支出と支払い税額の最小化のバランスで、どういった形の経営意思決定をするのかは、重要なポイントになってくると思います。
質問者2 先ほどの税優遇ですが、同じ従業員に投資するにあたって、研究費として投資するのか、開発費として投資するのか、総額は一緒でも研究開発費だと税制が優遇されることがあるので、その方が効果を見るのは難しいかもしれません。普通の開発だと普通の経費、研究開発費だと、経費プラスアルファの優遇がある、というのがあると思いますが、どうでしょう。 その方が伏在税を考えられないでしょうか。従業員の給与だと、この税制があろうとなかろうと、結果として出ると思います。しかし、研究費だったら補助が出るけれども、開発費だったら補助が出ないとなれば、企業として投資はするけれども、研究としての投資をするのか、開発としての投資をするのかという企業の選択があると思います。それに影響を与えることがあって、そのときの伏在税がどうなっているかということです。
安間 おっしゃる通りで、研究開発費は制度もありますので、伏在税を検討するセッティングとしては、使えるのではないかと思います。ただ、今回の問題として、システマティックに要件を満たしているというだけで利用企業を特定したので、そこからプラスアルファでどれだけ払っているかが肝になってくると思います。その分離をうまくできたら、プラスアルファで払った部分が、人材投資をした部分の税の資本化につながると考えています。そこは今後の検証課題になってくると思います。
質問者2 プラスアルファのところと分離できたらいいんですが、それは難しい。研究費か開発費かというのは、財務諸表に研究費として出ているから見たらわかります。ただ、その効果としては開発費だと1、2年後になって出てくるかもしれませんが、研究費だと3~5年後の成果になるかどうか難しいかもしれません。経営者としては、どちらかに振るだけの話なので、すごくわかりやすいのではないかと思いました。
安間 伏在税を明らかにしましょうという目的だけであれば、そういったセッティングも今後、データの入手可能性に左右されると思いますが、検証の可能性は広がるかもしれません。しかしながら、今回は、伏在税のみの検証を目的としたわけではなく、近年、議論が盛んな制度(賃上げ)の効果を見たかったので、新しく導入された制度に着目したところに研究のモチベーションがあります。ただし、そのモチベーションに対して伏在税の議論を入れてしまったがゆえに、少々ややこしくなってしまった部分があるかもしれません。議論や改正が盛んに行われていて、今も政策課題として重要性の高い賃上げについて、何かインプリケーションが得られるのではないかと、今回この題材を選びました。
村上 伏在税の話が出たので、聞きたいことがあります。伏在税の定義はScholesなどの税前利益、課税されているものと課税されていないもので、税前のリターンが変わるのはわかりやすいですが、賃上げも研究開発の減税もそうですが、本来、生産性が高い会社は、その制度がなくても投資しています。今回、この制度変更があって投資する会社は、ある意味下駄を履かされて投資しているわけなので、生産性が低いのは、その通りだと思っています。例えば、税前利益、税前リターンはすごく低い場合、それが伏在税というのかどうかがわからなかったんです。
安間 そうですね。そもそもScholesとWolfsonが最初に定義したimplicit taxesは、同じだけのキャッシュフローを生み出す財があったときに、片や税優遇されている方、片やされてないというところが議論のスタートだったと思います。そういった形で議論されていて、特定の資産を、研究対象、検証対象にしてその資産価格が制度変更の前後でどういった変化をしたかという研究が主です。実際に株価など資産の特定が比較的容易なものを、検証対象として分析されているものが多いです。最近は、その資産価格の議論がなくなってきているような印象を受けていて、企業レベルでの伏在税負担といった話が出てきています。資産の特定が難しいのが、このimplicit taxesの研究の一番の壁だと思います。企業レベルでどうかと考えるのも、implicit taxesを明らかにするための可能性をつかむ要因になると思います。
ただ、人件費は、私は課税優遇対象資産として人的資本投資と申し上げましたが、伏在税の例にあがるような建物などとは違うので、伏在税の議論の土俵に上げることに関しては、説明していく必要があると感じています。implicit taxes として定義できる範疇に入っているかどうかを固めないといけないと感じています。また、そもそもの生産性の高低など、ご指摘いただいた点を踏まえて検討を加えていかなければと思います。
鈴木 理屈の話になりますが、伏在税が生じるかどうかは、marginalな企業の話です。そのmarginalな企業だったら、税引後の利益率が一定になるように、課税優遇投資をしようがそうでない投資をしようが結果は一緒になります。理論的には均衡するので。その結果、伏在税が生じることになります。しかし、効率の悪い会社、つまりinfra marginalな会社は、伏在税が生じていない可能性があります。もともと業績が悪いだけの話であって、その辺は区別しないといけないと思っています。
賃上げ税制だけではなく、政策評価で租税特別措置を利用している企業の統計データを財務省は公表していますが、いろんな租税特別措置がある中で、賃上げ税制や経営力向上促進は利用頻度が高いです。その一方でほとんど利用されていない租税特別措置もあって、研究開発税制はあまり高くなかったのではないかと思います。つまり同じ租税特別措置、課税優遇措置がいろいろある中で、よく利用されているものと、そうでないものがあるというのは、伏在税の問題が影響している可能性があって、伏在税が大きいところは、課税優遇措置に企業が手を出さない可能性があるということ。そして、賃上げのように、infra marginalな会社がたくさんあって、とりあえずやろうというものは、利用頻度が高くなっている可能性もあるので、その辺はいろいろ実証的に分析されるといいのではないかと、感想になりますが思っています。
他に安間先生の報告に関して、何かご質問やご意見はありますでしょうか。
参加者3 人件費を増やしたからROE(Return On Equity:自己資本利益率)が下がるので、どう解釈するかになると思います。もともと業績が悪い会社が、税制がないときには人件費を増やさなかった。税制ができたから人件費を増やしてみる。税制に関係なく業績がよければ人件費を増やす会社を抽出するなら、ROEの計算で人件費を足し戻して計算すればいいのではないかと思います。計算の結果として、人件費を上げてからROEが下がったのか、もともとROEが低い会社がこの税制を利用するようになったのか、判明するかどうかわかりませんが、その解釈ができるのではないかと思います。やってみたらどうでしょうか。
安間 検討させていただきます。
鈴木 それと、設備投資や研究開発投資なら単発で終わるけれど、人件費の場合1度上げたらなかなか下げられないという事情があります。自信のない会社はどうしているかというと、ペースアップではなくてボーナスで上げています。ベースアップして賃上げした会社とボーナスでとりあえず賃上げした会社とを分けることができるのであれば、その会社の属性がわかれてくるので、伏在税の存在を識別できるかもしれません。
地道先生には、可能性の広がるような研究手法をご紹介いただきましたが、EBPMに向けた貢献や期待されるインプリケーションがあったら教えてください。
探索的ビッグデータ解析のEBPMへの貢献
地道 私は会計学者ではありませんので、会計学的な観点からのEBPMについてはコメントはできませんので、先にエクスキューズさせていただければ幸いです。ただし、EBPMという言葉を聞いたとき、エビデンスをどこの何に求めて、何のために必要性があるかということは重要な視点ではないかと思われます。統計科学的には、EBPMのベースになるのはデータだと思います。データを分析・解析した結果を、その分野に知見としてフィードバックすることが重要だと思います。最近、重要性が指摘されるEBPMの私なりの解釈は、主観だけでなく、客観的に集められたデータに基づいて意思決定をすることの重要性を、社会が求めているからであると理解しています。
私が会計データと本格的に関わったのは、2008年に日経NEEDS企業財務データのデータベースを作る学内プロジェクトに関わってからです。当時、商学部の学部長だった梶浦昭友先生から、データベースを作って学生や研究者にデータを潤沢に提供できる環境をつくってはどうかと提案されたことから、このプロジェクトに参加しました。まずは、会計データを潤沢に抽出するシステムを作ることになりました。3年の歳月がかかりましたが、幸いこの目的を達成するシステムをつくることができました。次に、財務データや会計データについて、それまでほとんど扱ったことがなかったため、このシステムからデータを抽出し、自分なりに可視化やモデリングをしてみました。このとき参考にしたのが、『ビジネス数理への誘い』という書籍です。この書籍は、椿 広計先生(現在、統計数理研究所所長)等が中心になって設置された、筑波大学ビジネス科学研究科における教科書の一冊と理解しています。この書籍の中には、特に売上高と人件費や資産合計を生産関数と会計データを用いて分析することが扱われていました。特に、バネの伸びに関するフックの法則などの物理式で表される法則が、社会科学の分野でも存在するかどうかというテーマにチャレンジした、非常に興味深い教科書でした。そこで議論されていることを参考に、私は売上高と従業員数、資産合計の関係を、日本の企業でみてみました。すると、非常に興味深い関係があるということがわかり、学内の紀要に論文としてまとめました。そのようなことを行っていたおりに、阪先生からお声がけいただいて、日本だけでなく世界中の上場・非上場企業についての財務データを一緒に解析し始めたのが会計データを本格的に扱うことになった出発点です。
世界中の企業の売上高などのデータを集めて、私が日本の企業のデータを解析した結果としてもっていた売上高と資産合計の関係についての知見 (エビデンス) を、世界中の上場企業や、非上場の企業を対象としたときはどうかを比較してみたところ、分布構造がよく似ていることがわかりました。例えば、約400万社の全世界の非上場企業の売上高と資産合計の散布図を手元のコンピュータで可視化したとき、これだけの規模のデータを可視化しているのは、おそらく、自分が初めてかもしれず、この可視化した結果そのものが、エビデンス以外の何物でもないのではないかと思いました。このような経験からも、対象となる現象から、適切にできる限り多くのデータをとったものを利用して得られた可視化などの結果は、エビデンスであり、事実そのものです。事実を事実として見るということが重要であることを実感するとともに、このような結果を会計学や、より広く社会へフィードバックすることが、探索的データ解析によるEBPMへの重要な貢献ではないかと思います。
阪 地道先生との研究で私のパートを紹介すると、2023年10月30日にIASB(国際会計基準審議会)の方が来訪され、気候関連の不確実性を扱うプロジェクトで意見を聞きたいということでした。そのとき、気候関連の不確実性について、なぜ財務諸表を扱うのか、会議に参加されていた実務家の方は疑問を持たれたと思います。IASBの方々に対して、財務諸表で扱っているものは、すべて確率変数であるということ、気候変動については不確実性が高まるかもしれないけれど、性質としては同じものであるということ、不確実性が高いときには何に留意しなければいけないのかを、実際にデータ分布などを示して、説明することができたのは、非常にいい経験でした。
また、どの企業をサステナビリティ企業の適応対象にすべきか、という金融審議会の議論の中で、時価総額で切るかとか、売上資産などの変数も見た方がいいのではないか、という意見が出ました。金融庁から、実際にそれぞれの変数で見たときにどれぐらい差が出てくるかを、証拠として出してほしいと相談を受けて、提示したことがあります。
何を見せるかについてすり合わせをする際に、これまでのさまざまな分析結果を活用して、すぐに提示できました。いろいろな角度から分析してきた知見が、実際、こういったエビデンスを提示するときにも活用できると感じました。
鈴木 EBPMの実例を挙げていただきありがとうございました。気候変動については、なぜ不確実な将来の話を財務諸表で開示するのか、という問題提起が、日本だけではなくて他国でもいわれているようです。ドイツなど特定の国が推進したがっているようですが、慎重にという意見が強いらしいです。その説得力を持たせるために、こういうデータが必要だということですね。
阪 そうですね。そのときに、私が申し上げたのが、不確実性が高いものについては、分布を知ることが重要だと思います。分布を知るためには、同じ事象については同じ会計処理をして、同じものを優遇するのが非常に大事です。まだデータが少ないので、同じものを出していく。これは出すのが難しいといって、代替的な情報の開示を求めるのでは駄目だ、ということと、分布が歪曲してしまうので、不正をさせない仕組みが必要だということです。
鈴木 実例を挙げていただきありがとうございました。
企業の税制適応行動に関する研究は、まだ緒に就いたばかりで、その政策立案や企業の経営戦略に本当に利用可能な形で証拠を提供できるかということになると、まだこれからいろいろ改善をしていかなければいけない途中であります。それは研究者の仕事だろうと思いますが、それと同時に実務に携わる方からも、「この研究はおかしい」「あれが抜けている」「これを調べてほしい」といった意見をフィードバックいただくことによって研究も進みますので、今後ともご協力いただきたいと思います。
ご登壇の皆さま、貴重なお話を紹介いただきありがとうございました。また、ご参加の皆さまもありがとうございました。
[i] McClure, C. G. (2023). How costly is tax avoidance? evidence from structural estimation. The Accounting Review, 98 (6).